
本記事では、Amazon CloudWatch Logsの基本設定からCloudWatch Logs Insightsを使った実務的なログ分析まで、SRE視点で解説します。
この記事でわかること
- CloudWatch Logsのロググループ・ログストリームの概念
- CloudWatchエージェントのインストールと設定手順
- メトリクスフィルターでエラーを自動検知する方法
- CloudWatch Logs Insightsの基本クエリと実務クエリ例
- 保存期間設計・コスト最適化のベストプラクティス
前提条件
- AWSアカウントがある
- EC2インスタンスが起動している(Amazon Linux 2 または Ubuntu)
- AWS CLIが設定済み(
aws configure完了)
なお、CloudWatchの全体像については「CloudWatch入門|SREが最初に設定すべき5つの機能と優先順位」を、アラームの設定方法については「CloudWatchアラートの設定方法|閾値・通知先をSRE視点で設計する手順」も合わせて参照してください。
CloudWatch Logsとは
Amazon CloudWatch Logsは、EC2・Lambda・ECS・オンプレミスサーバーなど、あらゆる環境のログを一元管理するAWSマネージドサービスです。
ログを収集するだけでなく、特定のパターンを検知してアラームを発火 したり、Insightsで複雑な集計・分析 を行ったりと、SREにとって欠かせない監視基盤の一つです。
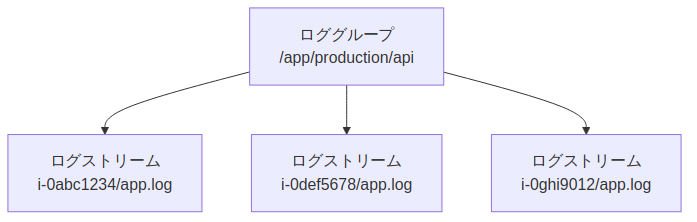
ロググループとログストリームの概念
CloudWatch Logsには2つの重要な概念があります。
| 概念 | 説明 | 例 |
|---|---|---|
| ロググループ | ログの論理的なグループ | /app/production/api |
| ログストリーム | 個々のリソースが出力するログの流れ | i-0abc1234/app.log |
ロググループは「どのアプリ・環境か」を表す単位で、ログストリームは「どのインスタンス・コンテナか」を表す単位です。
CloudWatchメトリクスとの違い
CloudWatchには「メトリクス」と「Logs」の2種類があり、役割が異なります。
| 種別 | データ形式 | 用途 |
|---|---|---|
| メトリクス | 数値(CPU使用率・リクエスト数等) | 傾向監視・SLO計測 |
| Logs | テキスト(ログファイルの内容) | 原因調査・エラー検知 |
SRE実務では、メトリクスで「異常を検知」し、Logsで「原因を特定」する使い分けが基本です。この2つを組み合わせることで、障害対応の MTTR(平均修復時間)を大幅に短縮できます。
SREがCloudWatch Logsを使う理由
CloudWatch Logsを活用することで、以下の実務課題が解決できます。
- SSH不要でログを確認できる: AWSコンソールまたはInsightsで直接検索可能。深夜の障害対応もスマートフォンから実施できます
- エラーの自動検知: メトリクスフィルターでエラーログをSlackに通知し、障害を見逃しません
- インシデント分析の高速化: Insightsで複数インスタンスのログを横断検索し、原因特定を数分で完了できます
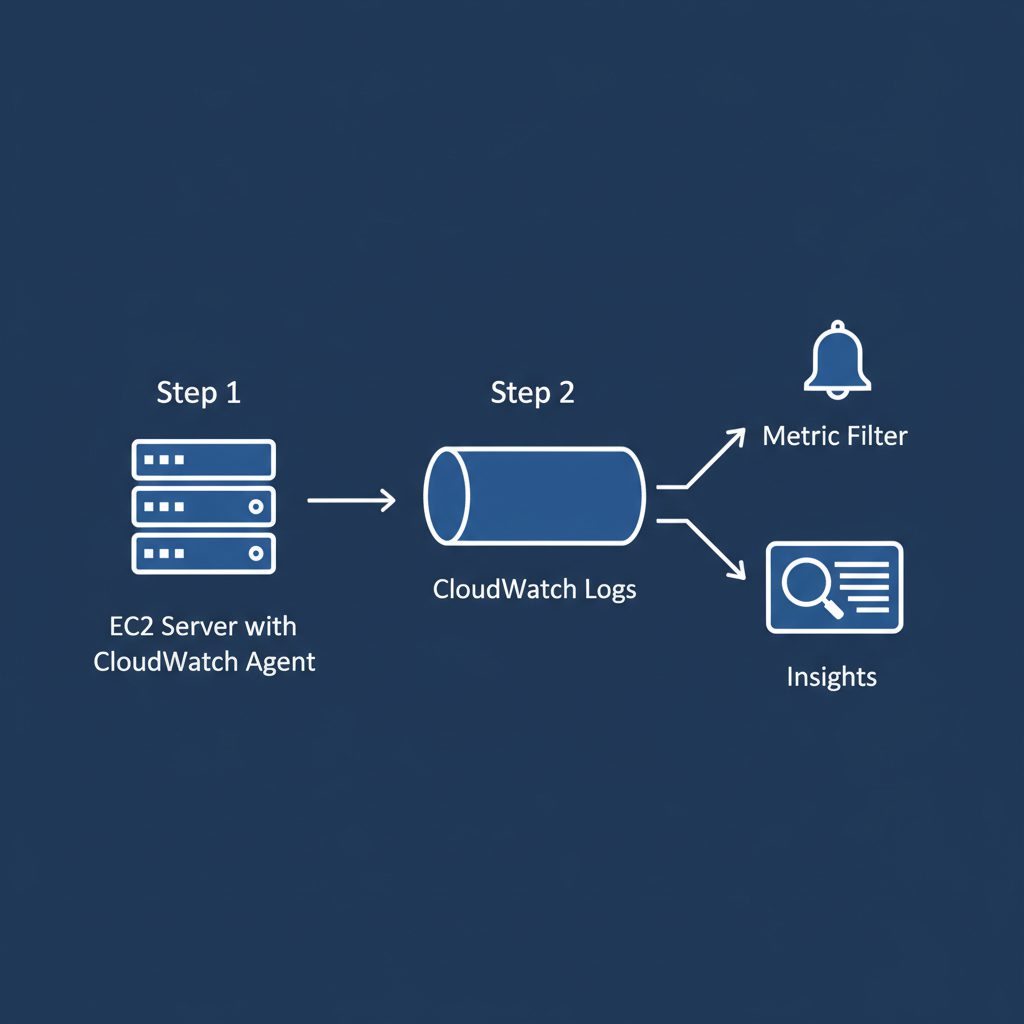
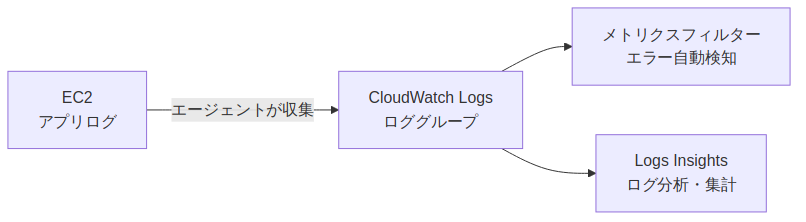
CloudWatch Logsの基本設定手順
EC2インスタンスのアプリケーションログをCloudWatch Logsに送信するには、CloudWatchエージェントを使います。全体の流れは以下の通りです。
Step 1: CloudWatchエージェントのインストール
Amazon Linux 2の場合:
sudo yum install -y amazon-cloudwatch-agent
Ubuntuの場合:
wget https://s3.amazonaws.com/amazoncloudwatch-agent/ubuntu/amd64/latest/amazon-cloudwatch-agent.deb
sudo dpkg -i -E ./amazon-cloudwatch-agent.deb
インストール後、バージョン確認を行います。
/opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a status
"status": "stopped" と表示されれば、インストール成功です。
Step 2: 設定ファイルの作成
設定ファイルは /opt/aws/amazon-cloudwatch-agent/bin/config.json に配置します。
以下は、 /var/log/app.log を CloudWatch Logs の /app/production/api に送信する設定例です。
{
"logs": {
"logs_collected": {
"files": {
"collect_list": [
{
"file_path": "/var/log/app.log",
"log_group_name": "/app/production/api",
"log_stream_name": "{instance_id}",
"timezone": "Asia/Tokyo"
}
]
}
}
}
}
| 設定項目 | 説明 |
|---|---|
file_path |
収集するログファイルのパス |
log_group_name |
送信先のロググループ名 |
log_stream_name |
ログストリーム名。{instance_id} でインスタンスIDを自動取得 |
timezone |
タイムゾーン。日本環境では Asia/Tokyo を指定 |
複数のログファイルを収集する場合は、collect_list に配列で追加します。
{
"logs": {
"logs_collected": {
"files": {
"collect_list": [
{
"file_path": "/var/log/app.log",
"log_group_name": "/app/production/api",
"log_stream_name": "{instance_id}/app",
"timezone": "Asia/Tokyo"
},
{
"file_path": "/var/log/nginx/error.log",
"log_group_name": "/app/production/nginx",
"log_stream_name": "{instance_id}/nginx-error",
"timezone": "Asia/Tokyo"
}
]
}
}
}
}
Step 3: エージェントの起動と動作確認
設定ファイルを指定してエージェントを起動します。
sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl \
-a fetch-config \
-m ec2 \
-s \
-c file:/opt/aws/amazon-cloudwatch-agent/bin/config.json
起動後、AWSコンソールの CloudWatch → 「ロググループ」で /app/production/api が作成されているか確認します。ログストリームにログが流れ始めれば設定完了です。
エージェントのログは以下で確認できます。
tail -f /opt/aws/amazon-cloudwatch-agent/logs/amazon-cloudwatch-agent.log

メトリクスフィルターでエラーを自動検知する
ログが流れてきたら、次は エラーログを自動検知してアラームに連携 する設定を行います。
メトリクスフィルターとは
メトリクスフィルターは、ログ内の特定パターンを検知して カスタムメトリクスの数値として記録 する機能です。
「ログに ERROR という文字が含まれるたびに ErrorCount メトリクスに +1 する」という設定が可能です。このメトリクスにアラームを設定することで、エラーログが一定数を超えたらSlackに通知できます。
エラーログフィルターの設定手順
CLIで設定する場合:
aws logs put-metric-filter \
--log-group-name /app/production/api \
--filter-name ErrorCountFilter \
--filter-pattern "ERROR" \
--metric-transformations \
metricName=ApplicationErrorCount,metricNamespace=App/Metrics,metricValue=1
AWSコンソールで設定する場合は以下の手順で行います。
- CloudWatch → 「ロググループ」→ 対象のロググループを選択
- 「メトリクスフィルター」タブ → 「メトリクスフィルターを作成」
- フィルターパターンに
ERRORを入力 - メトリクス名:
ApplicationErrorCount、名前空間:App/Metricsを設定 - 「作成」をクリック
JSONログを使っている場合は、より精度の高いフィルターを推奨します。
{ $.level = "ERROR" }
テキスト形式の ERROR フィルターは STACK_ERROR_CODE のような単語にも誤反応するため、JSONの特定フィールドを対象にする方が誤検知を減らせます。
フィルターからアラームへの連携
メトリクスフィルターで ApplicationErrorCount が記録されたら、CloudWatchアラームを設定してSNS経由でSlackに通知します。
例えば「5分間で10件以上のエラーが発生したら通知」というアラームを設定することで、障害の初動対応を自動化できます。
詳細なアラーム設定手順は「CloudWatchアラートの設定方法|閾値・通知先をSRE視点で設計する手順」で解説しています。

CloudWatch Logs Insightsでログを分析する
CloudWatch Logs Insightsは、ロググループに対して SQLライクなクエリを実行 してログを分析できる機能です。
障害発生時に複数インスタンスのログを横断検索したり、エラーの発生傾向を集計したりと、SRE実務でのインシデント対応を大幅に高速化できます。
基本クエリ構文
Insightsのクエリは以下の4つのコマンドで構成されます。
| コマンド | 役割 | 例 |
|---|---|---|
fields |
表示するフィールドを指定 | fields @timestamp, @message |
filter |
条件でログを絞り込む | filter @message like /ERROR/ |
stats |
集計を行う | stats count(*) as errorCount |
sort |
並び替え | sort @timestamp desc |
複数のコマンドをパイプ(|)でつなぐことで、段階的にログを絞り込んで分析できます。
実務で使うクエリ例
① エラーログを時系列で確認する
fields @timestamp, @message
| filter @message like /ERROR/
| sort @timestamp desc
| limit 50
直近のエラーログを50件表示します。障害発生直後にまず実行するクエリです。
② エラー発生件数を5分単位で集計する
fields @timestamp, @message
| filter @message like /ERROR/
| stats count(*) as errorCount by bin(5m)
| sort @timestamp desc
エラーがどのタイミングで急増したかを把握できます。インシデントのタイムライン作成に有効です。
③ レスポンスタイムの平均・最大値を集計する(JSON形式のログ向け)
fields @timestamp, responseTime
| filter ispresent(responseTime)
| stats avg(responseTime) as avgTime, max(responseTime) as maxTime by bin(1m)
| sort @timestamp desc
JSONで構造化されたログからレスポンスタイムを分析します。SLI(レイテンシ)の実態把握に使えます。
④ IPアドレス別のエラー件数を集計する
fields @timestamp, @message, clientIp
| filter @message like /4[0-9][0-9]/
| stats count(*) as errorCount by clientIp
| sort errorCount desc
| limit 20
特定のIPアドレスからの異常なリクエストを検知できます。DDoS対策の初動調査に有効です。
⑤ 特定のリクエストIDを追跡する
fields @timestamp, @message, requestId
| filter requestId = "abc-1234-def"
| sort @timestamp asc
1つのリクエストが複数のサービスをまたぐ場合、リクエストIDを使ってログを連結することでエラーの発生箇所を特定できます。
クエリ結果をダッシュボードに追加する
よく使うInsightsクエリはCloudWatchダッシュボードに追加して、日常的な監視に組み込めます。
- Insightsでクエリを実行
- 「ダッシュボードに追加」ボタンをクリック
- 追加先ダッシュボードを選択(または新規作成)
「5分単位のエラー件数推移」「レスポンスタイム推移」などをダッシュボードに登録しておくことで、障害時に即座に状況を把握できます。
SREが実践するベストプラクティス
保存期間の設計
CloudWatch Logsのデフォルト保存期間は 無期限 です。コスト最適化のため、用途に合わせて保存期間を設定します。
| ログの種類 | 推奨保存期間 | 理由 |
|---|---|---|
| アプリケーションログ | 30〜90日 | インシデント調査の実績から |
| セキュリティ・監査ログ | 1年以上 | コンプライアンス対応 |
| デバッグログ | 7〜14日 | 直近の調査にのみ使用 |
CLIで保存期間を設定する例:
aws logs put-retention-policy \
--log-group-name /app/production/api \
--retention-in-days 30
全ロググループの保存期間を一括確認するには:
aws logs describe-log-groups \
--query 'logGroups[*].[logGroupName,retentionInDays]' \
--output table
構造化ログ(JSON)への移行
テキスト形式のログはInsightsでの分析効率が低いため、アプリケーションログをJSON形式に統一することを推奨します。
{
"timestamp": "2026-04-02T10:00:00+09:00",
"level": "ERROR",
"message": "Database connection timeout",
"requestId": "abc-1234-def",
"responseTime": 5023,
"clientIp": "203.0.113.1",
"userId": "user-789"
}
JSON形式にすることで、Insightsで filter $.level = "ERROR" のような精度の高いクエリが使えるようになります。また、メトリクスフィルターでも特定フィールドの値を正確に検知できます。
コスト最適化とS3連携
CloudWatch Logsの主なコストは データインジェスト(取り込み) と ストレージ です。
コスト削減のポイント:
- 保存期間を必ず設定する: 無期限はストレージコストが増大します
- 不要なデバッグログを除外する: アプリ側でDEBUGレベルのログを本番で出力しない
- 長期保存・大量ログはS3に流す: S3のストレージコストはCloudWatch Logsより大幅に安価です
S3エクスポートの2つの方法
① 手動エクスポート(create-export-task)
過去ログを指定期間でS3にまとめてエクスポートします。定期的にLambdaやEventBridgeでスケジュール実行することで自動化できます。
aws logs create-export-task \
--task-name export-api-logs \
--log-group-name /app/production/api \
--from 1700000000000 \
--to 1700086400000 \
--destination your-s3-bucket-name \
--destination-prefix api-logs/2026/04
--from と --to にはUnixタイムスタンプ(ミリ秒)を指定します。注意点として、同一ロググループに対する同時エクスポートタスクは1件のみ実行可能です。
② リアルタイム自動エクスポート(Subscription Filter → Firehose → S3)
ログが流れるたびにリアルタイムでS3へ転送する方式です。Kinesis Data Firehoseを経由することで、遅延なく継続的にS3へ蓄積できます。
# Firehoseデリバリーストリームを作成(S3宛先)
aws firehose create-delivery-stream \
--delivery-stream-name cloudwatch-logs-to-s3 \
--s3-destination-configuration \
RoleARN=arn:aws:iam::123456789012:role/firehose-role,\
BucketARN=arn:aws:s3:::your-log-bucket,\
Prefix=logs/,\
BufferingHints="{SizeInMBs=128,IntervalInSeconds=300}"
# ロググループにサブスクリプションフィルターを設定
aws logs put-subscription-filter \
--log-group-name /app/production/api \
--filter-name to-firehose \
--filter-pattern "" \
--destination-arn arn:aws:firehose:ap-northeast-1:123456789012:deliverystream/cloudwatch-logs-to-s3
--filter-pattern "" で全ログをFirehoseに流します。特定のパターンのみ絞り込むことも可能です。
監視ログとアーカイブログを分ける設計
ログ量が多い環境では、CloudWatch Logsに流すログを絞り込み、コストを抑えながら監視品質を維持する設計が有効です。
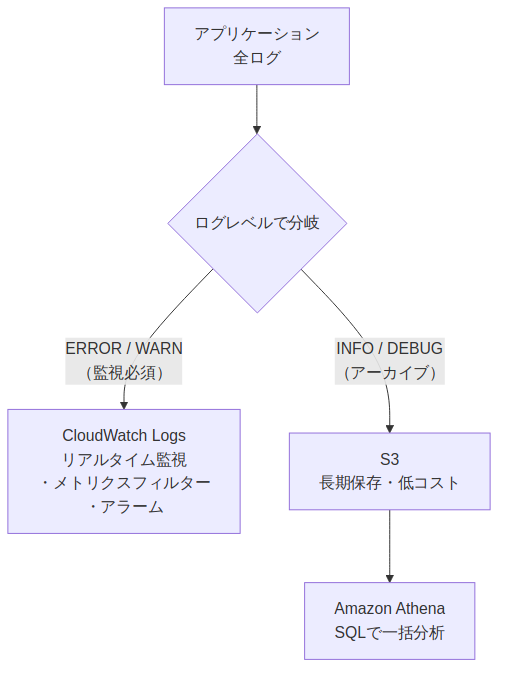
| ログの種類 | 送信先 | 目的 |
|---|---|---|
| ERROR / WARN | CloudWatch Logs | リアルタイム監視・アラーム発火 |
| INFO / DEBUG | S3 | 長期保存・障害後の詳細調査 |
この設計のメリットは3点あります。
- コスト削減: CloudWatch Logsに流すデータ量を最小化できる(INFOログはS3の方が10〜20倍安価)
- ノイズ低減: Insightsで検索するログが絞られ、障害時の原因特定が高速化する
- 大量データ分析: S3のINFO/DEBUGログはAthenaでSQLクエリを実行でき、Insightsでは難しいクロス集計も可能
AthenaでS3ログを分析する
S3に蓄積したログをAthenaで分析するには、まずテーブルを定義します。
CREATE EXTERNAL TABLE app_logs (
timestamp STRING,
level STRING,
message STRING,
requestId STRING,
responseTime INT,
clientIp STRING
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
LOCATION 's3://your-log-bucket/logs/'
TBLPROPERTIES ('has_encrypted_data'='false');
テーブル作成後は通常のSQLで分析できます。
-- 過去7日間のエラー件数を日別に集計
SELECT
DATE(CAST(timestamp AS TIMESTAMP)) AS log_date,
COUNT(*) AS error_count
FROM app_logs
WHERE level = 'ERROR'
AND timestamp >= DATE_FORMAT(DATE_ADD('day', -7, NOW()), '%Y-%m-%dT%H:%i:%s')
GROUP BY DATE(CAST(timestamp AS TIMESTAMP))
ORDER BY log_date DESC;
CloudWatch Logs Insightsと比較したAthenaの優位点は、パーティション設計によるスキャンコスト削減と大規模データへの対応です。数億件のログを横断集計する場合はAthenaの方が適しています。
まとめ
本記事で解説した内容を整理します。
- CloudWatch Logsの概念: ロググループ(アプリ・環境単位)とログストリーム(インスタンス単位)の2層構造
- エージェント設定:
amazon-cloudwatch-agentをインストールし、収集ファイルと送信先ロググループを設定 - メトリクスフィルター: ログ内のパターン(
ERROR等)を検知してカスタムメトリクスを生成し、アラームに連携 - Logs Insights: 4つのコマンド(fields / filter / stats / sort)で柔軟にログを分析。障害時の原因特定を高速化
- ベストプラクティス: 保存期間の設定・JSON構造化ログ・コスト最適化
CloudWatch Logsを使いこなすことで、SSH不要でログを確認でき、インシデント対応の MTTR(平均修復時間)を大幅に短縮できます。
SREとしてCloudWatchをより深く学びたい方へ
CloudWatch Logsの設定からSLO設計・アラーム運用まで、実務的なSRE監視設計を体系的に学べるUdemyコースを公開しています。
▶ AWS×SRE入門〜CloudWatchで学ぶ監視設計の基礎〜を見てみる
CloudWatchをずんだもん解説で楽しく学べる入門コースです。SRE転職を目指しているエンジニアにもおすすめです。


コメント