
本記事では、Amazon CloudWatch Logs Insightsのクエリ構文と、SRE実務でよく使うパターン10選を解説します。
この記事でわかること
- CloudWatch Logs Insightsの基本クエリ構文(fields / filter / stats / sort / parse)
- 障害調査・パフォーマンス分析・コスト監視で使えるクエリパターン10選
- Insightsを使う上での注意点(コスト・件数上限・タイムゾーン)
- AWSコンソールでのInsights操作手順
前提条件
- AWSアカウントがある
- CloudWatch Logsにログが収集されている(エージェント設定済み、またはLambda/ECS等からの自動収集)
CloudWatch Logsの基本設定については「CloudWatch Logsの使い方完全ガイド|SREが実務で使うログ監視・Insights分析」を合わせて参照してください。
CloudWatch Logs Insightsとは
CloudWatch Logs Insightsは、CloudWatch Logsに収集されたログを SQLライクな独自クエリ言語 で検索・集計できる分析機能です。
複数のロググループを横断して検索でき、結果をグラフとして可視化することもできます。SSH接続やサードパーティツール不要で、AWSコンソールから直接ログの詳細分析が行えます。
CloudWatch Logs Insightsが解決する課題
ログ調査でよくある課題と、Insightsが提供する解決策を整理します。
| 課題 | Insightsの解決策 |
|---|---|
| 複数インスタンスのログを横断検索できない | 複数ロググループを一括クエリ |
| エラーが何件あるか数えられない | stats count() で集計 |
| 特定リクエストのログを追跡できない | filter requestId = "xxx" で絞り込み |
| どのエンドポイントが遅いか特定できない | stats avg(responseTime) by endpoint |
CloudWatch Logsとの関係
Insightsは CloudWatch Logs の 追加機能 であり、独立したサービスではありません。CloudWatch Logsにデータが収集されていれば、追加設定なしでInsightsを使い始められます。
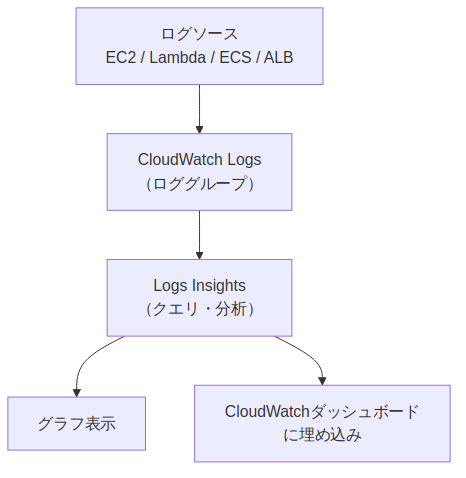

CloudWatch Logs Insightsの基本クエリ構文
Insightsのクエリ言語は5つのコマンドで構成されます。それぞれのコマンドを | で連結して使います。
fields @timestamp, @message
| filter @message like /ERROR/
| stats count(*) by bin(5m)
| sort @timestamp desc
| limit 100
fieldsコマンド ——表示するフィールドを指定する
fields @timestamp, @message, @logStream
fields で表示したいフィールドを指定します。@timestamp(タイムスタンプ)・@message(ログ本文)・@logStream(ログストリーム名)はInsightsが自動で付与する組み込みフィールドです。
JSON形式のログであれば、fields level, message, requestId のようにフィールド名を直接指定できます。
filterコマンド ——条件で絞り込む
filter @message like /ERROR/ # 部分一致(正規表現)
filter level = "ERROR" # 完全一致
filter responseTime > 1000 # 数値比較
filter @message not like /health/ # 否定
like は正規表現による部分一致です。完全一致の場合は = を使います。複数条件は and / or で結合できます。
filter level = "ERROR" and service = "payment"
statsコマンド ——集計する
stats count(*) as errorCount by bin(5m)
stats avg(responseTime) by endpoint
stats count(*) by level
stats は最も強力なコマンドです。count()・avg()・sum()・max()・min()・pct() などの集計関数が使えます。
bin(5m) は時間軸でのグループ化です。1m・5m・1h などの単位で指定します。
sortとlimitコマンド ——並べ替えと件数制限
sort responseTime desc # レスポンスタイムの大きい順
limit 20 # 上位20件のみ表示
sort の後に asc(昇順)または desc(降順)を指定します。limit はデフォルト1,000件のところ、任意の件数に制限できます。
parseコマンド ——非構造化ログを解析する
parse @message "* * * *" as method, path, statusCode, responseTime
JSON形式でないプレーンテキストのログに対して、parse でフィールドを抽出できます。正規表現を使ったより高度な抽出も可能です。
parse @message /(?<statusCode>\d{3}) (?<responseTime>\d+)ms/

よく使うクエリパターン10選
パターン1:エラーログを絞り込む
障害発生時に最初に使うパターンです。特定の時間帯に発生したエラーを素早く抽出します。
fields @timestamp, @message, @logStream
| filter @message like /ERROR/
| sort @timestamp desc
| limit 50
活用場面: アラート発火後の初動調査。どのインスタンスで何のエラーが出ているかを最速で確認できます。
JSONログの場合は filter level = "ERROR" に変えると、ログ本文中の “ERROR” という単語に反応しない分、ノイズが減ります。
パターン2:エラー件数を時系列で集計する
単なる絞り込みではなく、「いつからエラーが増えたか」を可視化します。
fields @timestamp, @message
| filter @message like /ERROR/
| stats count(*) as errorCount by bin(5m)
| sort @timestamp asc
このクエリは結果を 棒グラフ で表示でき、CloudWatchダッシュボードに埋め込むことも可能です。デプロイや設定変更のタイミングとエラー数の増加が一目で相関できます。
パターン3:レスポンスタイムが遅いリクエストを特定する
パフォーマンス劣化の調査で使います。応答時間が閾値を超えたリクエストのみを抽出します。
fields @timestamp, requestId, path, responseTime
| filter responseTime > 2000
| sort responseTime desc
| limit 30
responseTime > 2000 は2,000ミリ秒(2秒)以上のリクエストを絞り込む例です。ログのフィールド名はアプリケーションの実装に合わせて変更してください。
パターン4:エンドポイント別の平均レスポンスタイムを集計する
どのAPIが全体的に遅いかを俯瞰的に確認します。
fields path, responseTime
| stats avg(responseTime) as avgTime,
max(responseTime) as maxTime,
count(*) as requestCount
by path
| sort avgTime desc
| limit 20
avg・max・count を組み合わせることで、「平均は速いが稀に極端に遅い」エンドポイントも検出できます。
パターン5:特定のリクエストIDでログを追跡する
分散システムで特定リクエストの処理フローを追跡する際に使います。
fields @timestamp, @message, @logStream
| filter requestId = "abc123-def456"
| sort @timestamp asc
複数のサービス・コンテナにまたがるリクエストも、リクエストIDが一貫して付与されていれば、複数ロググループを選択してこのクエリを実行することで横断追跡できます。
パターン6:LambdaのタイムアウトとエラーをCold Startと分けて集計する
Lambda固有のログ構造に対応したパターンです。
fields @timestamp, @message
| filter @message like /Task timed out/ or @message like /ERROR/ or @message like /REPORT/
| stats count(*) as count by @message
| sort count desc
| limit 10
Lambda の実行ログには REPORT 行にDuration(実行時間)とMax Memory Usedが含まれます。タイムアウト直前のDurationを確認するには以下のクエリが有効です。
fields @timestamp, @message
| filter @message like /REPORT/
| parse @message "Duration: * ms" as duration
| filter duration > 25000
| stats count(*) as timeoutRisk by bin(1h)
パターン7:ALBアクセスログを分析する
ALBのアクセスログをCloudWatch Logsに転送している場合に使えるパターンです。
fields @timestamp, @message
| parse @message '* * * * * * * * * * * "* *" "* * *"' as
type, time, elb, client_ip, target, request_processing_time,
target_processing_time, response_processing_time, elb_status_code,
target_status_code, received_bytes, sent_bytes, request_verb,
request_url, http_version, ssl_cipher, ssl_protocol
| filter elb_status_code like /5/
| stats count(*) as errorCount by elb_status_code, request_url
| sort errorCount desc
| limit 20
HTTP 5xx エラーが多いURLを一覧化できます。エラーページや特定エンドポイントの問題を素早く特定できます。
パターン8:ECS・Kubernetesのコンテナログを分析する
ECS・EKS環境では複数コンテナのログが1つのロググループにまとまっています。コンテナ名でフィルタリングします。
fields @timestamp, @message, @logStream
| filter @logStream like /payment-service/
| filter @message like /ERROR/
| stats count(*) as errorCount by bin(10m)
| sort @timestamp asc
@logStream はコンテナID・タスクIDを含むため、特定サービスのログストリームに絞る場合は like で部分一致指定します。
パターン9:特定IPアドレスからのアクセスを追跡する
セキュリティ調査や不審なアクセス調査で使います。
fields @timestamp, @message
| filter @message like /192.168.1.100/
| sort @timestamp asc
| limit 100
like でIPアドレスを部分一致指定します。JSON構造化ログであれば filter clientIp = "192.168.1.100" のように完全一致で絞り込む方が確実です。
パターン10:ログの急激な減少(サービス停止の疑い)を検知する
ログが突然出なくなるケースはサービス停止・エージェント障害のサインです。5分ごとのログ件数を出して異常を可視化します。
fields @timestamp, @message
| stats count(*) as logCount by bin(5m)
| sort @timestamp asc
通常時のログ件数と比較して、ある時点から急激に減少していれば、アプリケーションの停止や CloudWatch エージェントの障害が疑われます。

Insightsを使う上での注意点
タイムゾーンはUTCで管理される
Insightsのタイムスタンプは UTC(協定世界時) で表示されます。日本時間(JST = UTC+9)に変換して確認する必要があります。
AWSコンソールの時間入力フォームも UTC で指定します。「日本時間の15時」に発生した障害を調査する場合は、「06:00 UTC」と入力してください。
スキャンデータ量に比例してコストが発生する
Insightsのクエリは スキャンしたデータ量(GB単位)に課金 されます(2026年時点:0.0076 USD/GB)。
コストを抑えるポイントは以下の通りです。
- 時間範囲を絞る: 24時間ではなく1〜2時間に限定するだけでコストが大幅に下がります
- クエリ対象ロググループを絞る: 全ロググループではなく調査対象に絞る
- limit を活用する: 全件取得が不要な場合は
limit 100等を指定する
クエリ結果は最大10,000件
1回のクエリで返せる結果は 最大10,000件 です。それ以上のデータを取得する場合は時間範囲を分割してクエリを実行するか、S3へのエクスポートを検討してください。
また、1アカウントあたり同時実行できるInsightsクエリ数には上限があります(デフォルト30クエリ)。大量のダッシュボードウィジェットを一度に更新する場合は注意が必要です。
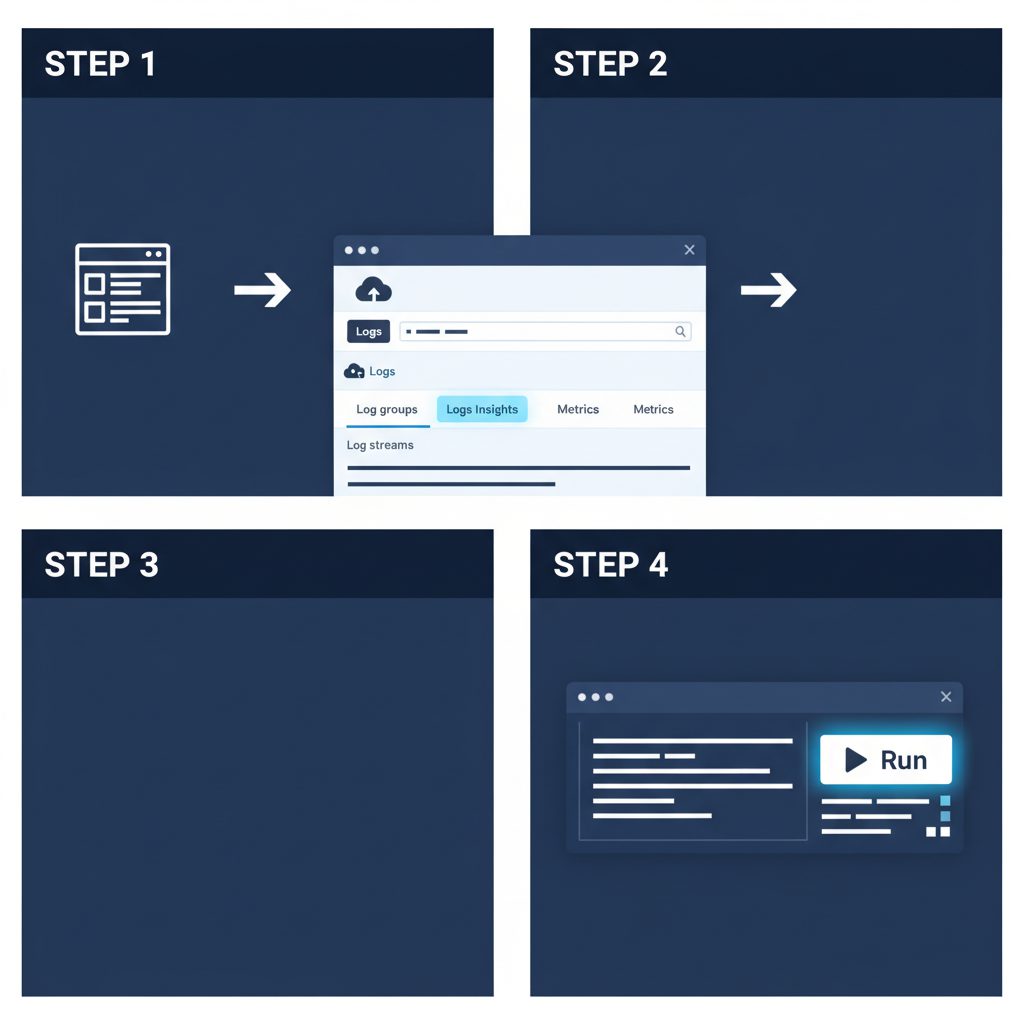
コンソールでのInsights操作手順
Step 1:Insightsページを開く
AWSコンソールにログインし、「CloudWatch」→ 左メニューの「ログ」→「Logs Insights」を選択します。
Step 2:クエリ対象のロググループを選択する
ページ上部の「ロググループを選択」から1つ以上のロググループを選択します。複数選択すると横断検索が可能です。
Step 3:時間範囲を指定する
右上の時間範囲セレクターで検索対象の期間を指定します。「相対」(過去1時間・過去24時間等)と「絶対」(日時を直接指定)が選べます。
Step 4:クエリを入力して実行する
クエリエディタにクエリを貼り付けて「クエリを実行」ボタンをクリックします。結果が下部に表示され、stats コマンドを使ったクエリはグラフとして可視化されます。
Step 5:よく使うクエリを保存する
「クエリを保存」ボタンでクエリに名前をつけて保存できます。チーム共有フォルダに保存することで、インシデント時にすぐ呼び出せます。
Step 6:ダッシュボードに追加する
グラフ表示状態で「ダッシュボードに追加」ボタンをクリックすると、CloudWatchダッシュボードにInsightsウィジェットとして埋め込めます。定点観測に有効です。
まとめ
本記事で解説した内容を整理します。
- 基本構文:
fields・filter・stats・sort・limit・parseの6コマンドを組み合わせる - パターン1〜2: エラーログの絞り込みと時系列集計——障害の初動調査で最初に使う
- パターン3〜4: レスポンスタイム分析——どのリクエスト・エンドポイントが遅いかを特定する
- パターン5: リクエストID追跡——分散システムでのトレース調査
- パターン6: Lambda固有のタイムアウト・エラー監視
- パターン7: ALBアクセスログの5xxエラー集計
- パターン8: ECS・Kubernetesのコンテナログ横断分析
- パターン9: 不審なIPアドレスのアクセス追跡
- パターン10: ログ減少によるサービス停止の疑い検知
- 注意点: UTCタイムゾーン・スキャンコスト・10,000件上限を把握しておく
CloudWatch Logs Insightsを使いこなすことで、障害調査の MTTR(平均修復時間)を大幅に短縮できます。まずはパターン1・2・3を手元の環境で試してみてください。
CloudWatchの全体像については「CloudWatch入門|SREが最初に設定すべき5つの機能と優先順位」、アラーム設定については「CloudWatchアラートの設定方法|閾値・通知先をSRE視点で設計する手順」も合わせて参照してください。
SREとしてCloudWatchをより深く学びたい方へ
CloudWatch Logs Insightsの活用からSLO設計・インシデント対応まで、SRE実務に必要なスキルを体系的に学べるUdemyコースを公開しています。
▶ AWS×SRE入門〜CloudWatchで学ぶ監視設計の基礎〜を見てみる
ずんだもん解説で楽しく学べる入門コースです。SRE転職を目指しているエンジニアにもおすすめです。


コメント