
この記事でわかること
– 実際のSRE求人票に頻出するスキル要件の全体像
– AWSエンジニアがすでに持っているスキルと「補うべきスキル」の仕分け
– 転職までの具体的な学習ロードマップ(3ヶ月×2ステップ)
– SRE技術面接でよく聞かれる質問と答え方
この記事の対象読者
AWS を使ったインフラ・バックエンド経験が 1〜3 年あり、SRE へのキャリアチェンジを検討しているエンジニア。
SRE 求人票を開くたびに「Terraform・Kubernetes・SLO 設計…」と並ぶスキル要件を見て、「どこから手をつければいいんだ」と閉じてしまっていませんか?
AWS は日常的に使っていても、「SRE として通用するレベルかどうか」の自信がないまま時間だけが過ぎると、気づけば同じポジションで何年も経過してしまいます。SRE 求人の競争は年々激化しており、レバテックキャリアだけで 610 件超の募集が出ている一方で、応募者のスキルレベルも上がり続けています。
この記事では実際の SRE 求人票を逆算して「本当に求められる AWS スキル」と「学ぶべき優先順位」を体系的に解説します。読み終わる頃には、今日から動ける学習計画が手に入ります。

SRE転職の求人票に書いてある「必須スキル」を分解する
よく出るキーワード TOP10(実際の求人票ベース)
実際の SRE 求人票(レバテックキャリア・Findy・Green に掲載されている求人)を調査したところ、以下のキーワードが頻出していました。
| 順位 | キーワード | 出現率(目安) | 分類 |
|---|---|---|---|
| 1 | AWS(EC2・EKS・RDS・CloudFront など) | ほぼ全件 | クラウド |
| 2 | Terraform / AWS CDK | 約 80% | IaC |
| 3 | Kubernetes / EKS | 約 75% | コンテナ |
| 4 | CloudWatch / Datadog / Prometheus | 約 70% | 監視 |
| 5 | SLI / SLO / エラーバジェット | 約 65% | SRE概念 |
| 6 | GitHub Actions / CI/CD | 約 65% | 自動化 |
| 7 | Python / Go / Bash | 約 60% | スクリプト |
| 8 | インシデント対応 / ポストモーテム | 約 55% | 実務経験 |
| 9 | Linux コマンド / シェルスクリプト | 約 50% | 基礎 |
| 10 | セキュリティ(IAM・VPC 設計) | 約 45% | セキュリティ |
AWS が「ほぼ全件」に登場するのは当然として、注目すべきは Terraform と Kubernetes が 2・3 位を占めている 点です。「AWS を使える」だけでは不十分で、「IaC でインフラを管理できる」「コンテナ環境を運用できる」が最低ラインになってきています。
「必須」と「あれば尚可」の見分け方
求人票の読み方として、以下の基準で仕分けると整理しやすくなります。
必須(書類落ちに直結)
– 「必須要件」「Required」に明記されているもの
– 求人票の冒頭に書かれているもの
– 経験年数が指定されているもの(「Terraform 2 年以上」など)
あれば尚可(加点要素)
– 「歓迎要件」「Nice to have」に書かれているもの
– 「あれば尚可」「経験者優遇」という表現
– 資格(AWS 認定など)の多くはここに分類される
資格については、AWS 認定はほとんどの求人で「必須」ではなく「加点」 です。資格取得に時間を使うより、実務スキルを磨く方が転職活動では有利に働きます。
AWSエンジニアがすでに持っているスキルはどれか
AWS エンジニアとして 1〜3 年の経験があれば、上記 TOP10 のうち以下はすでにカバーできている可能性が高いです。
既存スキルとして使えるもの
– AWS(EC2・RDS・CloudFront・IAM・VPC)の構築・運用経験
– CloudWatch の基本的な設定(アラート・ログ確認)
– Linux コマンド・シェルスクリプトの基礎
– GitHub / Git を使った開発フロー
補う必要があるもの
– Terraform を使った IaC 実務(設計・運用レベル)
– Kubernetes / EKS の実運用経験
– SLI / SLO の設計・実装経験
– インシデント対応フローの設計とポストモーテム文化
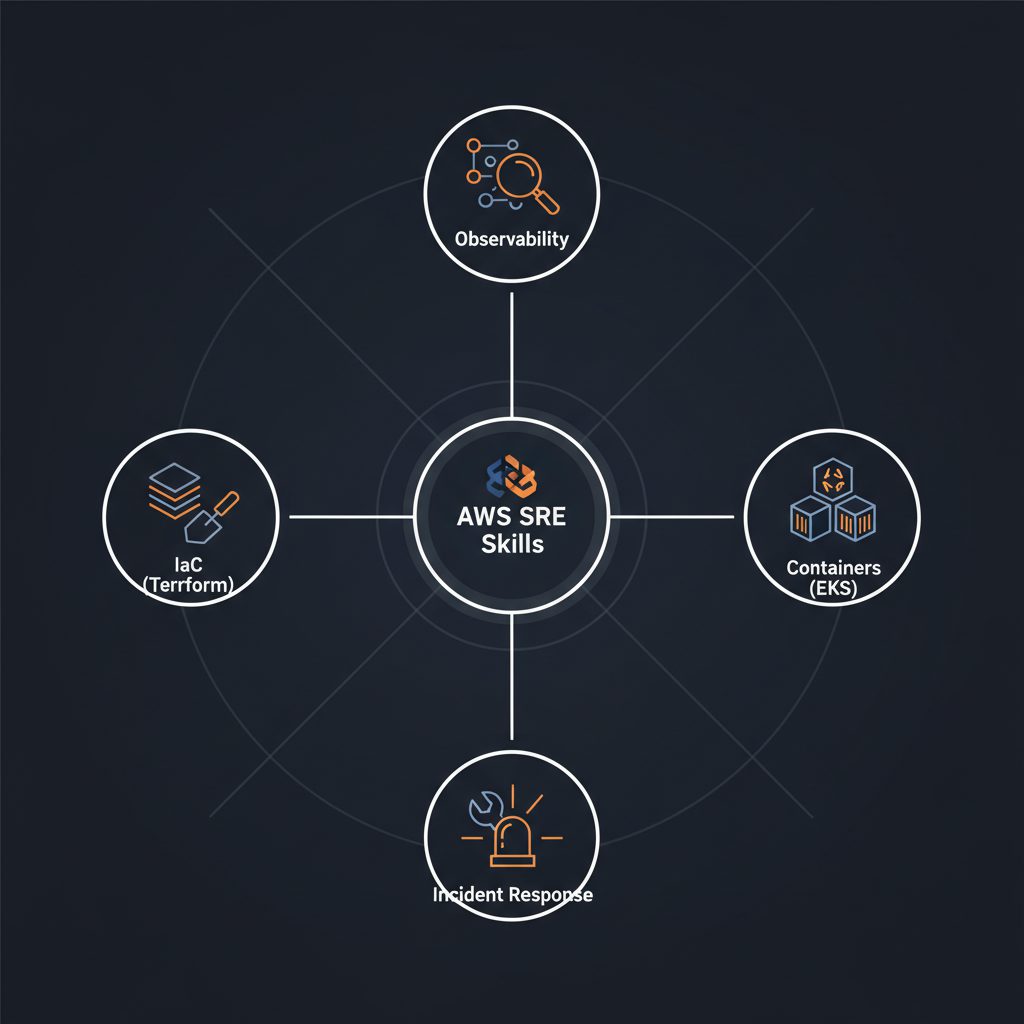
AWSエンジニアがSREに転職するために「補うべき」スキル4つ
① オブザーバビリティ設計(CloudWatch Application Signals・SLO・SLI)
CloudWatch を「アラートを設定するツール」として使っているだけでは、SRE の役割を果たせません。SRE に求められるのは、システムの信頼性を数値で定義し、継続的に計測・改善する仕組みを設計する力 です。
具体的には以下を理解・実装できる必要があります。
- SLI(Service Level Indicator): 何を計測するかを定義する。例)「API のエラーレート」「レスポンスタイムの P99」
- SLO(Service Level Objective): SLI の目標値を設定する。例)「直近 30 日間のエラーレートを 0.1% 以下に保つ」
- エラーバジェット: SLO を下回った分を「使えるエラーの余裕」として管理し、開発速度とのバランスを取る
AWS では CloudWatch Application Signals を使うことで、SLI・SLO・エラーバジェットを UI から直接設定・可視化できます(2024年 GA)。従来は Metrics と Logs Insights を手組みする必要がありましたが、Application Signals により SLO 運用の難易度が大幅に下がりました。
まず CloudWatch Application Signals で「SLO を 1 本設定・運用する」ところから始めると、SRE 的な思考が実践的に身につきます。
② IaC実務経験(Terraform)
Terraform は「環境構築を自動化するツール」という認識で止まっているエンジニアが多いですが、SRE に求められるのは 本番環境のインフラを安全に変更・管理できるレベルの Terraform 経験 です。
求人票でよく見る要件と、それに対応するスキルは以下の通りです。
| 求人票の要件 | 必要なスキル |
|---|---|
| 「Terraform で AWS 環境を管理した経験」 | VPC・EC2・RDS・IAM などのリソースを .tf ファイルで管理 |
| 「tfstate の管理経験」 | S3 + DynamoDB によるリモートステート管理 |
| 「Terraform モジュール化の経験」 | 再利用可能なモジュール設計ができる |
| 「複数環境(dev/stg/prod)の管理」 | workspace またはディレクトリ分割による環境管理 |
個人学習で Terraform を触ったことがある程度では不十分で、GitHub Actions と組み合わせた CI/CD パイプラインで Terraform を自動実行する経験 があると転職市場での評価が大きく上がります。
③ コンテナ運用(EKS・Kubernetes基礎)
Kubernetes は「知っている」と「運用できる」の差が大きいスキルです。SRE として求められるのは Kubernetes の概念理解だけでなく、本番環境での Pod の障害対応・スケーリング設計・監視設定ができること です。
AWSエンジニアが最初に押さえるべき EKS の知識は以下です。
- クラスター設計: ノードグループの構成、スポットインスタンスの活用
- Pod 障害対応:
kubectl describe podでのエラー確認、ログの取り方 - 監視設定: CloudWatch Container Insights による CPU・メモリ・ネットワーク監視
- IAM 連携: EKS Pod Identity / IRSA(IAM Roles for Service Accounts)の設定
ECS Fargate の経験があれば、コンテナの概念は理解できているはずです。EKS は ECS より運用の自由度が高い分、覚えることが増えますが、ECS との違いを意識しながら学ぶと習得が早くなります。
④ インシデント対応フロー(ポストモーテム・オンコール設計)
技術スキルだけでなく、インシデントが起きたときにどう動くか を説明できることが SRE 面接では重視されます。
SRE のインシデント対応フローの基本は以下の通りです。
検知(CloudWatch アラート → PagerDuty / Slack 通知)
↓
初動対応(影響範囲の特定・暫定対処)
↓
恒久対応(根本原因の特定・修正・デプロイ)
↓
ポストモーテム(blameless な振り返り・再発防止策)
特に ポストモーテム(障害振り返り) は、「誰が悪かったか」ではなく「システムとして何を改善するか」を議論する文化で、Google SRE 本で提唱されている概念です。面接でインシデント対応経験を聞かれたとき、このフローに沿って答えられると評価が高まります。
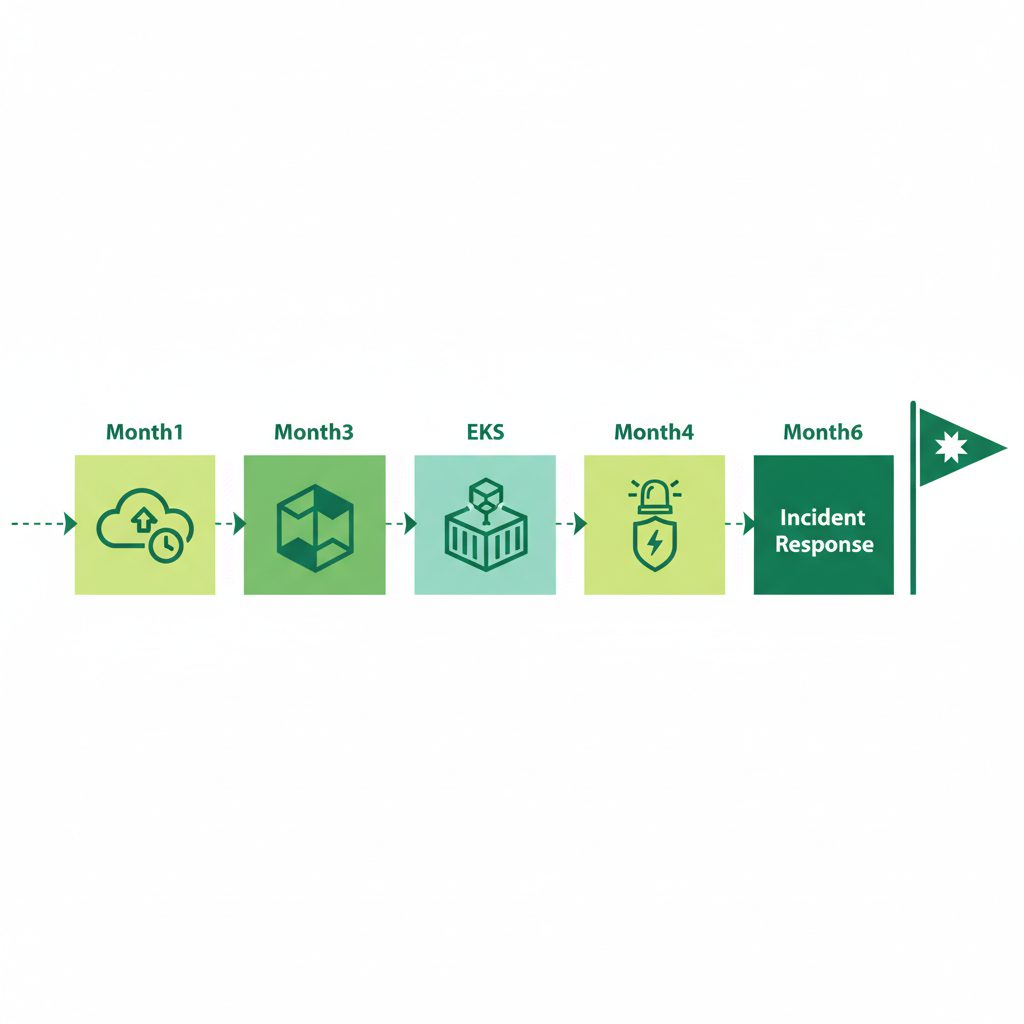
スキル習得の優先順位と学習ロードマップ
まず3ヶ月でやること(CloudWatch深掘り+Terraform入門)
SRE転職に向けた学習で最初の3ヶ月は「今持っているAWSスキルを深める」ことに集中します。新しいツールに手を広げるより、CloudWatch と Terraform を実務レベルまで引き上げること が最優先です。
Month 1: CloudWatch Application Signals でSLO設計を体験する
既存のAWS環境(個人アカウントでも可)に Application Signals を有効化し、簡単なWebアプリに対してSLOを1本設定してみます。
やること:
1. CloudWatch Application Signals を有効化
2. SLI として「エラーレート」を選択
3. SLO を「直近30日間のエラーレート 1% 以下」に設定
4. エラーバジェットの消費状況をダッシュボードで確認
Month 2〜3: Terraform で既存のAWS環境をコード化する
EC2・VPC・セキュリティグループなど、すでに手動で作った構成を Terraform でコード化する練習をします。新規に作るより「既存環境の再現」の方が実務に近く、理解が深まります。
やること:
1. terraform import で既存リソースを取り込む
2. .tf ファイルに書き直し、terraform plan でドリフトを確認
3. S3 + DynamoDB でリモートステートを設定
4. GitHub Actions で terraform plan を自動実行するパイプラインを作る
この3ヶ月で「SLOの概念を説明できる」「TerraformでAWS環境を管理した経験がある」が職務経歴書に書けるようになります。
次の3ヶ月(EKS・Kubernetes・インシデント対応の深掘り)
後半3ヶ月は「コンテナ運用」と「インシデント対応フロー」に集中します。
Month 4〜5: EKSクラスターを構築・運用してみる
eksctl または Terraform で EKS クラスターを構築し、簡単なアプリをデプロイして運用を体験します。
やること:
1. Terraform で EKS クラスターを構築(eksctl でも可)
2. kubectl で Pod のデプロイ・スケーリングを操作
3. CloudWatch Container Insights で CPU・メモリ監視を設定
4. Pod が起動しないエラーを意図的に起こし、kubectl describe で原因特定を練習
Month 6: インシデント対応フローを設計してドキュメント化する
実際に障害を起こさなくても、「もし本番でこの障害が起きたらどう対応するか」をドキュメントとして書く練習が有効です。これがそのままポートフォリオになります。
作成するドキュメント:
- Runbook(障害対応手順書): 「EKS Pod が全滅した場合の初動対応」
- ポストモーテムテンプレート: タイムライン・根本原因・再発防止策
- SLO違反時のエスカレーションフロー図
このドキュメントを GitHub に公開しておくと、面接で「実際に見せてください」と言われたときに使えます。
転職活動と並行してやること(ポートフォリオ・職務経歴書)
学習が半分ほど進んだ段階で、転職活動の準備を並行して始めます。
職務経歴書に書けるようになる表現(Before → After)
| Before(転職前) | After(学習後) |
|---|---|
| 「AWSでサーバーを構築・運用していました」 | 「TerraformでEC2・VPC・RDSをIaC管理し、GitHub ActionsでCI/CDパイプラインを構築」 |
| 「CloudWatchでアラートを設定していました」 | 「CloudWatch Application Signalsを用いてSLO設計・エラーバジェット管理を導入」 |
| 「障害対応の経験があります」 | 「Runbook・ポストモーテムテンプレートを整備し、インシデント対応フローを設計」 |
数値と固有名詞を入れるだけで、同じ経験でも伝わり方が大きく変わります。
SRE転職でよく聞かれる技術面接の質問と答え方
SLOとSLAの違いを説明してください
SRE面接の定番質問です。以下の整理を頭に入れておきましょう。
| 用語 | 定義 | 例 |
|---|---|---|
| SLI | 計測する指標 | エラーレート・レイテンシ・可用性 |
| SLO | 社内で定める目標値 | 「エラーレートを30日間で0.1%以下」 |
| SLA | 顧客との契約上の保証値 | 「可用性99.9%を保証。未達時は返金」 |
模範回答の型:
「SLIは計測する指標そのもの、SLOはそのSLIに対して社内チームが合意した目標値です。SLAはSLOをベースに顧客と締結する契約で、SLOより少し低い値に設定するのが一般的です。SLOを守るためにエラーバジェットを管理し、開発速度とのバランスを取るのがSREの役割だと理解しています。」
インシデント発生時の初動対応を教えてください
経験がない場合でも、フローを覚えておけば答えられます。
「まずCloudWatchアラートやPagerDutyの通知で検知したら、影響範囲と重要度(P1〜P3)を判断します。P1の場合は即座に関係者をSlackのインシデントチャンネルに集め、暫定対処(トラフィック切り替え・ロールバック)を優先します。サービスが復旧した後、24〜48時間以内にポストモーテムを開催し、タイムラインと根本原因・再発防止策を全員で確認します。」
TerraformでどんなAWS構成を管理しましたか
ここは正直に話した上で、学習内容を補足するのが有効です。
「業務では○○を管理していました。加えて個人的にVPC・EKSクラスター・RDSをTerraformでコード化し、S3リモートステートとGitHub ActionsによるCI/CDパイプラインも構築しました。tfstateのロックやdestroy対策など、本番運用を意識した設計を心がけました。」
まとめ
AWSエンジニアがSRE転職で求められるスキルをまとめると、以下の4つを補うことが最短ルートです。
- オブザーバビリティ設計 — CloudWatch Application Signals でSLO/SLIを実装できる
- IaC実務 — TerraformでAWS環境を管理し、CI/CDパイプラインと連携できる
- コンテナ運用 — EKSでPodの障害対応・スケーリング・監視ができる
- インシデント対応フロー — Runbook・ポストモーテムを設計・運用できる
学習期間の目安は 6ヶ月。最初の3ヶ月でCloudWatchとTerraform、後半3ヶ月でEKSとインシデント対応に集中することで、転職活動に必要なスキルセットが整います。
自分のAWSスキルが今のSRE求人に通用するか、まずプロに確認してみませんか?
レバテックキャリアでは IT エンジニア専門のキャリアアドバイザーが無料で現状のスキルを診断し、マッチする求人を提案してくれます。求人票を眺めているだけより、プロの目線で「あと何が必要か」を明確にしてもらう方が、学習計画も立てやすくなります。
👉 自分のAWSスキルがSRE転職に通用するか、プロに無料で診断してもらう(レバテックキャリア)
転職を急いでいなくても、今の市場価値を知るだけでも登録する価値があります。
👉 まず求人票だけ見てみる(登録3分・完全無料)(レバテックキャリア)
コメント