
CloudWatchのアラームを設定したものの、誤検知が多くて通知を無視するようになっていませんか?
「とりあえずCPU使用率が80%を超えたらアラート」という設定を入れたまま放置していると、業務時間中に毎日アラートが飛んでくるようになります。気づけば「またアラートか」という状態になり、本当の障害を見落とすリスクが高まります。これがSRE界隈でいう「アラートのオオカミ少年化」です。
本記事では、CloudWatchアラームの 閾値設計・通知先設計の指針 を体系的に解説します。誤検知を減らしつつ、障害を確実に検知するアラーム設計の考え方と、AWSコンソールでの具体的な設定手順まで紹介します。
この記事でわかること
– CloudWatchアラームの仕組みと3つの状態
– 閾値の決め方(静的閾値 vs 異常検知の使い分け)
– SLI/SLOから閾値を逆算する方法
– SNSトピックを使った通知先の設計パターン
– アラームの誤検知を減らす期間設定のコツ
AWSの基本操作とCloudWatchの概要(メトリクス・アラームとは何か)を知っている方を対象としています。
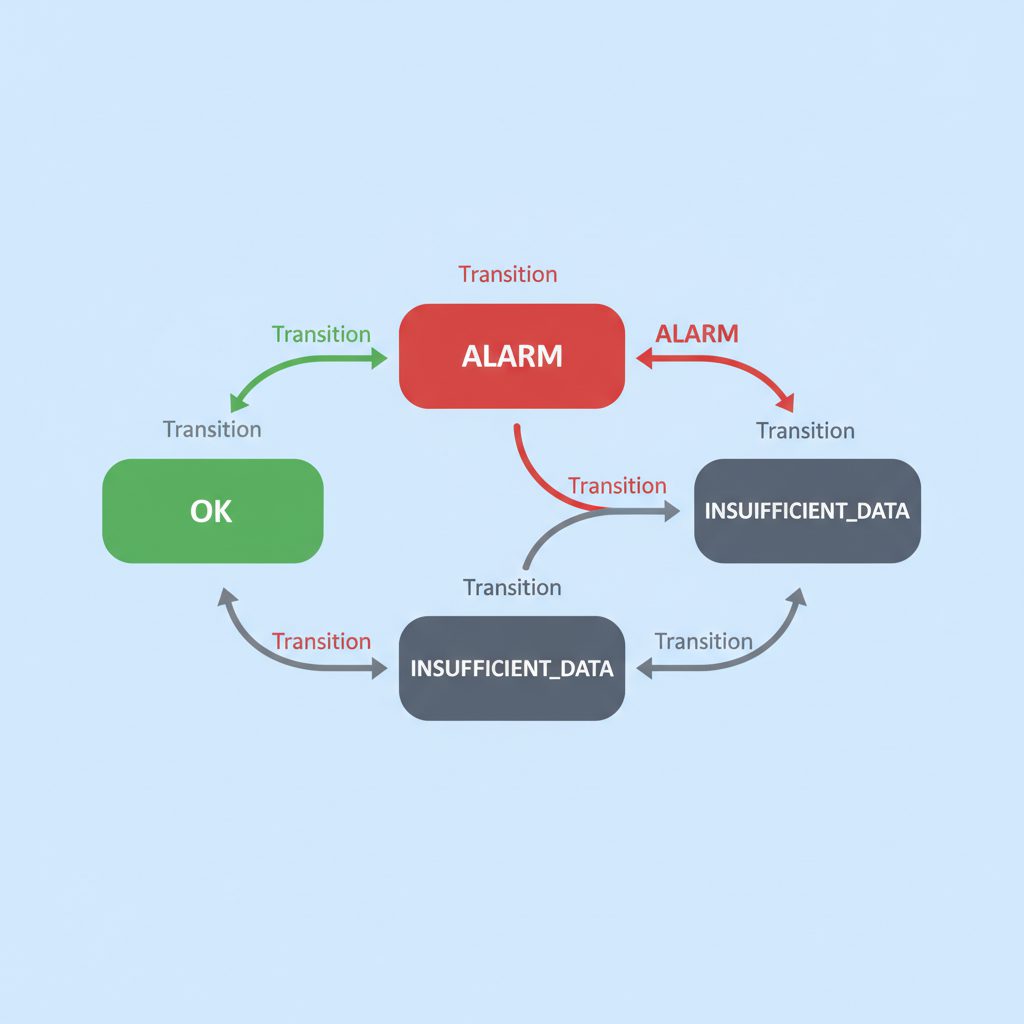
CloudWatchアラームの基本構造
アラームを構成する3つのコンポーネント
CloudWatchアラームは、以下の3つの要素で構成されています。
| コンポーネント | 役割 | 設定例 |
|---|---|---|
| メトリクス | 監視対象の数値データ | EC2のCPU使用率、ALBのリクエスト数 |
| 閾値(Threshold) | アラームを発火させる条件 | CPUUtilization > 70% が 3回連続 |
| アクション | アラーム状態になったときの動作 | SNSトピックへ通知、EC2の自動スケール |
この3つを正しく設計することで、「必要なときだけ通知が来る」アラームを実現できます。
アラームの3つの状態
CloudWatchアラームは常に以下のいずれかの状態を持ちます。
graph LR OK["✅ OK 閾値内"] ALARM["🔴 ALARM 閾値超過"] INSUF["⚪ INSUFFICIENT_DATA データ不足"] OK -->|"閾値を超えた"| ALARM ALARM -->|"閾値内に戻った"| OK INSUF -->|"データ受信再開"| OK OK -->|"データが届かなくなった"| INSUF ALARM -->|"データが届かなくなった"| INSUF
INSUFFICIENT_DATA はメトリクスのデータが届いていない状態です。EC2インスタンスを停止した直後や、CloudWatchエージェントが止まっているときに発生します。この状態をアラーム扱いにするか無視するかは、ユースケースによって判断が分かれます。
評価期間(Evaluation Period)の仕組み
アラームが発火するまでには「評価期間」と「データポイント数」の設定が関係します。
評価期間: 5分間隔 × 3回分のデータポイント
発火条件: 3回中3回が閾値を超えた場合にALARM状態へ移行
この設定により、一時的なスパイクではアラームが発火せず、継続的な問題のみを検知できます。誤検知対策として、この 「M out of N」(N回中M回) の設定は非常に重要です。
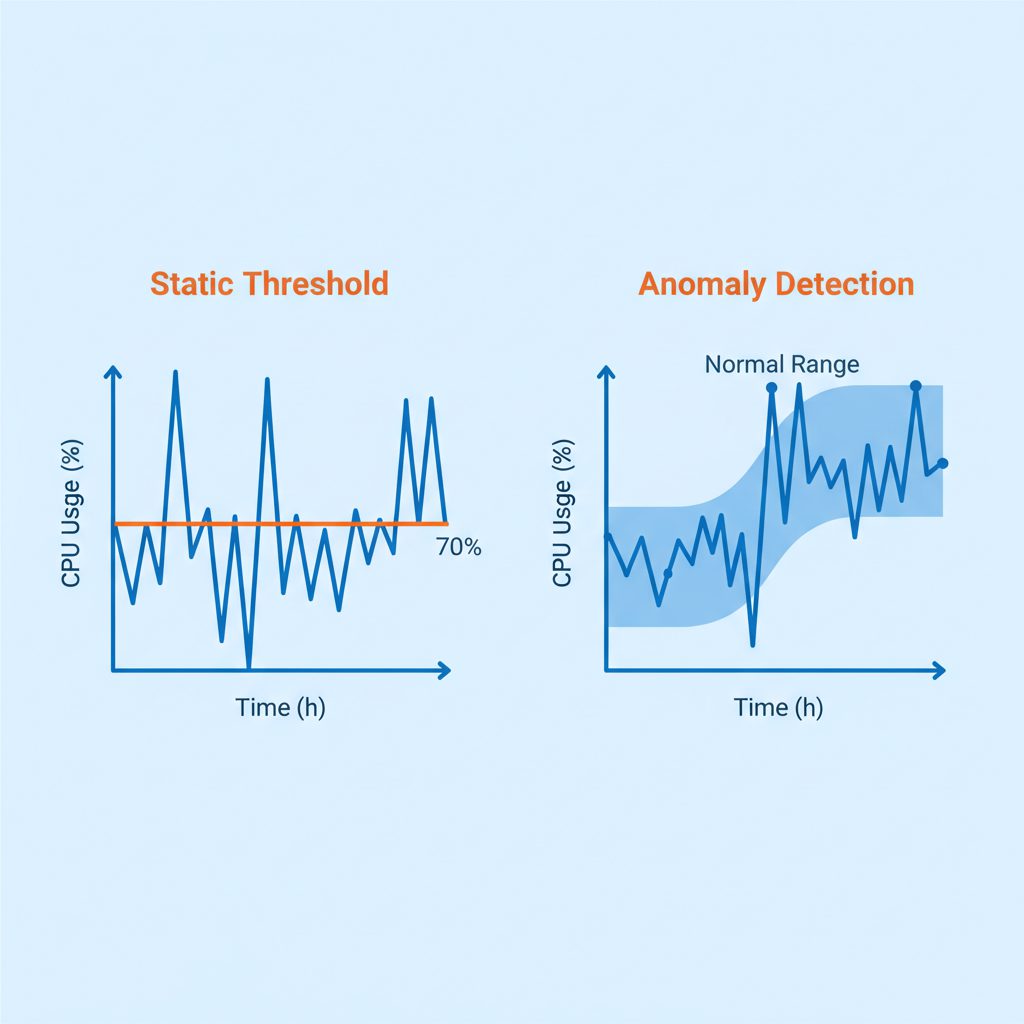
閾値の設計指針
静的閾値 vs 異常検知(Anomaly Detection)
CloudWatchの閾値設定には2種類のアプローチがあります。
静的閾値(Static Threshold)
固定の数値でアラームを設定する方法です。シンプルで設定が容易ですが、トラフィックパターンが変動するシステムでは誤検知が増えやすいです。
例: CPUUtilization > 80% を 5分間隔で3回連続検知したらアラート
適したケース:
– リソース使用率の上限が明確に決まっている
– 夜間・昼間でトラフィックの差が少ない
– SLOで「〇〇%以下」と数値が決まっている
異常検知(Anomaly Detection)
機械学習を使って「正常範囲のバンド」を自動計算し、そこから外れた場合にアラームを発火させる方法です。曜日・時間帯のパターンを学習するため、EC系のような変動があるシステムに向いています。
例: CPUUtilizationが過去2週間の同時刻の平均±2σの範囲を外れたらアラート
適したケース:
– 朝と夜でトラフィックが大きく異なる
– 週次のバッチ処理が走るシステム
– 季節性・周期性のあるサービス
SLI/SLOから閾値を逆算する方法
SREとしてアラームを設計する際、最も本質的なアプローチは SLOから閾値を逆算する ことです。
例として、「可用性99.9%」のSLOを設定しているサービスのアラームを考えます。
SLO: 月次エラーレート < 0.1%(= エラーバジェット: 0.1%)
↓
エラーレートが 0.05% を超えたら「エラーバジェットの50%消費」でアラート
エラーレートが 0.08% を超えたら「エラーバジェットの80%消費」でページング
このように、「インフラ的な閾値」ではなくユーザー影響に直結する指標 でアラームを設計することで、アラートの重要度が明確になります。
CloudWatchで設定する場合、ALBの HTTPCode_Target_5XX_Count または TargetResponseTime をメトリクスとして使い、以下のように設定します。
メトリクス数式(Metric Math):
エラーレート = HTTPCode_Target_5XX_Count / RequestCount * 100
閾値: エラーレート > 0.05 で ALARM
評価: 1分間隔 × 5回中3回
誤検知・検知漏れを減らす期間設定
閾値の数値だけでなく、「評価期間」と「データポイント数」の設定が誤検知率に大きく影響します。
| 設定パターン | 特徴 | 適したケース |
|---|---|---|
| 1回/1分で即発火 | 検知漏れが少ないが誤検知が多い | クリティカルな決済処理 |
| 3回中3回/5分 | バランスが取れた標準設定 | 一般的なWebサービス |
| 5回中3回/5分 | 誤検知を抑えるが検知に遅れ | バッチ処理・非同期系 |
推奨: 「3回中3回/5分」を基準に始め、実運用の誤検知状況を見て調整する
また、 treat_missing_data の設定も重要です。データが届かなかった場合をどう扱うかを指定します。
| 設定値 | 意味 | 推奨場面 |
|---|---|---|
missing |
データなし(INSUFFICIENT_DATA) | デフォルト。通常はこれ |
breaching |
閾値超過として扱う | インスタンス停止=問題と見なしたい場合 |
notBreaching |
正常として扱う | 定期バッチで停止が想定される場合 |
ignore |
評価に含めない | スポットインスタンスなど |
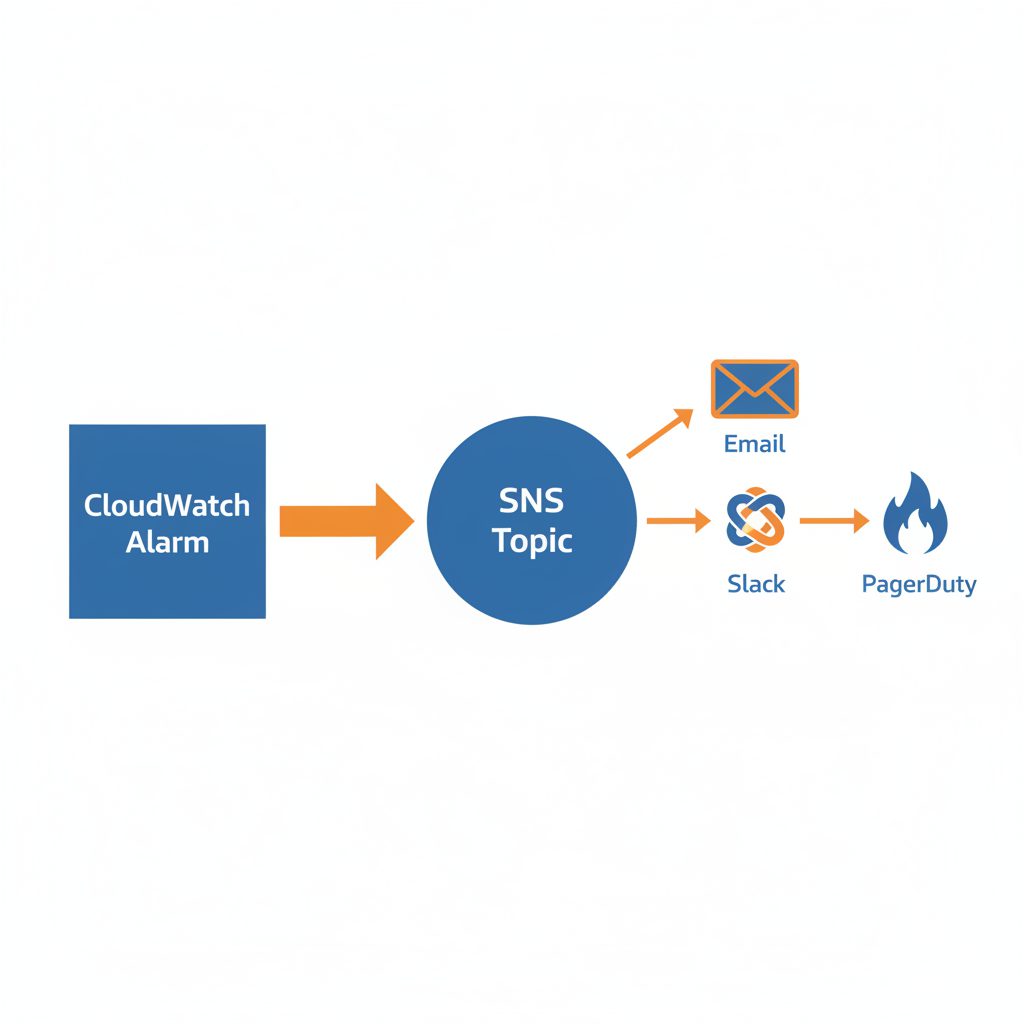
通知先の設計指針
SNSトピックの構成パターン
CloudWatchアラームの通知は SNS(Simple Notification Service) トピックを経由して送信されます。SNSトピックをどう設計するかで、通知の柔軟性が大きく変わります。
パターン1: 重要度別にトピックを分ける(推奨)
sns-critical → PagerDuty(ページング)+ Slack #alert-critical
sns-warning → Slack #alert-warning
sns-info → Slack #alert-info(業務時間内のみ)
このパターンは、アラームの重要度に応じて通知先・通知方法を変えられるため、アラート疲れを防げます。
パターン2: サービス別にトピックを分ける
sns-api-service → APIチームのSlackチャンネル
sns-batch-service → バッチチームのSlackチャンネル
sns-infra → インフラチームのSlackチャンネル
チーム規模が大きく、責任範囲が明確に分かれている場合に有効です。
パターン3: 環境別にトピックを分ける
sns-prod-critical → PagerDutyページング
sns-staging-warning → Slackのみ
本番と非本番で通知の緊急度を分けるベーシックな設計です。
アラートレベルと通知先の対応
SREの現場では、アラートの重要度(Severity)に応じて対応者・対応時間帯を変えるのが一般的です。
| Severity | 状況 | 通知先 | 対応時間 |
|---|---|---|---|
| P1(緊急) | SLOバジェット消費 >50%、サービス停止 | PagerDuty(ページング)+ Slack | 24時間 |
| P2(高) | エラー率上昇、レイテンシ劣化 | Slack #alert-critical | 業務時間 |
| P3(中) | リソース使用率の上昇傾向 | Slack #alert-warning | 翌営業日 |
| P4(低) | 情報通知(デプロイ完了など) | Slack #alert-info | 不要 |
CloudWatchアラームにP1〜P4の概念を対応させると、以下のように整理できます。
graph TD
A["CloudWatch Alarm"] --> B{重要度判定}
B -->|"SLOに直結"| C["SNS: sns-critical
→ PagerDuty + Slack"]
B -->|"リソース閾値"| D["SNS: sns-warning
→ Slack #alert-warning"]
B -->|"情報通知"| E["SNS: sns-info
→ Slack #alert-info"]
Slack・PagerDuty連携の設定例
Slack連携(ChatbotまたはLambda経由)
AWSのChatbotサービスを使うと、SNSトピック → Slackチャンネルへの転送をノーコードで設定できます。
1. AWS Chatbot コンソールを開く
2. 「Slack ワークスペース」を設定
3. 「チャンネル設定」から対象チャンネルを追加
4. 「通知」タブで SNS トピックを登録
PagerDuty連携(SNS経由)
1. PagerDutyで「AWS CloudWatch」インテグレーションを作成
2. 発行されたWebhook URLをコピー
3. SNSトピックにHTTPS サブスクリプションを追加(URLにWebhookを貼り付け)
4. サブスクリプションの確認(PagerDutyが自動で応答)
CloudWatchアラームの設定手順(AWSコンソール)
実際にAWSコンソールでアラームを設定する手順を解説します。ここでは「ALBのエラーレート監視」を例に取ります。
Step 1: CloudWatchコンソールでアラームを作成する
- AWSコンソール → CloudWatch → 「アラーム」→「アラームの作成」
- 「メトリクスの選択」をクリック
Step 2: メトリクスと閾値を設定する
今回はメトリクス数式(Metric Math)を使ってエラーレートを計算します。
メトリクス1(m1): ApplicationELB > HTTPCode_Target_5XX_Count
期間: 1分
統計: Sum
メトリクス2(m2): ApplicationELB > RequestCount
期間: 1分
統計: Sum
数式(e1): (m1 / m2) * 100
ラベル: ErrorRate
閾値の設定:
閾値の種類: 静的
条件: ErrorRate > 0.5(エラーレートが0.5%を超えたら)
アラームを実行するデータポイント: 3/3(3分中3回)
Step 3: SNSトピックへの通知を設定する
アラーム状態のアクション:
SNSトピック: sns-warning(既存トピックを選択 or 新規作成)
OK状態のアクション:
SNSトピック: sns-warning(復旧通知も同じトピックへ)
復旧通知(OK状態へのアクション)も設定しておくと、「障害が解消した」ことを自動で通知できます。
Step 4: アラーム名と説明を設定する
アラーム名: prod-alb-error-rate-warning
説明: ALBのエラーレートが0.5%を超えた場合に通知。SLO閾値の50%消費に相当。
命名規則の推奨:
{環境}-{リソース種別}-{メトリクス}-{重要度}
例:
prod-ec2-cpu-warning
prod-alb-error-rate-critical
staging-rds-connection-info
命名規則を統一しておくと、アラーム一覧での絞り込みや、Terraformでの管理が容易になります。

よくある失敗パターンと対策
アラートの「オオカミ少年化」を防ぐ
最も多い失敗が、アラートが多すぎて無視されるようになるケースです。
原因と対策:
| 原因 | 対策 |
|---|---|
| 閾値が低すぎる(CPU 50%でアラート等) | 実運用データを見て閾値を調整。P50/P95を参考にする |
| 評価データポイントが少ない(1回で発火) | 「3回中3回」「5回中3回」に変更 |
| 情報通知が多すぎる | P3/P4はSlackの低優先チャンネルへ分離 |
| 復旧通知が邪魔 | 復旧通知は別チャンネルへ、または無効化 |
定期的なアラームレビューを実施する
月1回、以下の観点でアラームを見直します。
1. 過去1ヶ月で発火したアラーム一覧を確認
2. 「アクションなし」で終わったアラームを特定
3. 閾値・評価期間を調整 or 削除
INSUFFICIENT_DATAへの対処
EC2インスタンスのスケールイン・スケールアウト時や、インスタンス停止時に INSUFFICIENT_DATA が発生します。
対策:
# Terraform例: INSUFFICIENT_DATAをアラーム扱いにしない
resource "aws_cloudwatch_metric_alarm" "cpu_warning" {
alarm_name = "prod-ec2-cpu-warning"
comparison_operator = "GreaterThanThreshold"
evaluation_periods = 3
metric_name = "CPUUtilization"
namespace = "AWS/EC2"
period = 300
statistic = "Average"
threshold = 80
treat_missing_data = "notBreaching" # ← スケールイン時を正常扱い
}
Auto Scalingグループ配下のインスタンスでは、treat_missing_data = "notBreaching" または "ignore" が適切です。
アラーム数増加によるコスト管理
CloudWatchアラームは1つあたり月0.10USD(標準解像度)です。数百〜数千のアラームを作成すると、コストが積み上がります。
コスト削減のポイント:
1. Composite Alarm(複合アラーム)の活用
→ 複数のアラームをAND/OR条件でまとめ、通知を1本化
2. 高解像度メトリクスの使用を限定する
→ 1秒解像度は0.30USD/月。通常は60秒で十分
3. 不要なアラームを定期削除する
→ AWS Configルール or Lambdaで未使用アラームを検出
Composite Alarmの設定例:
ALARM("prod-alb-error-rate-warning") OR
ALARM("prod-alb-5xx-count-warning")
→ どちらかが発火したら1つのアラームとして通知
まとめ
本記事では、CloudWatchアラームの閾値・通知先設計の指針を解説しました。
この記事のポイント
– アラームは「メトリクス・閾値・アクション」の3つで構成される
– 閾値は SLI/SLOから逆算 するのが本質的なアプローチ
– 静的閾値は明確な上限がある場合、異常検知はトラフィックが変動するシステムに適する
– SNSトピックは重要度別(Critical / Warning / Info)に分けると管理しやすい
– 「3回中3回/5分」の評価設定が誤検知対策の基本
– treat_missing_data をユースケースに合わせて設定することで誤報を防げる
アラーム設計の次のステップは、CloudWatch Logsを組み合わせたエラー調査の仕組み化です。本シリーズの次の記事「CloudWatch Logsの使い方」も参考にしてください。
CloudWatchを使ったSREの監視設計を体系的に学びたい方には、以下のUdemyコースがおすすめです。アラーム設計・SLO管理・ダッシュボード構築まで、ハンズオンで学べます。

コメント