CloudWatchの機能が多すぎて、何から設定すればいいかわからない——そう感じたことはないでしょうか。
「とりあえずデフォルトのアラームだけ入れた」という状態が続くと、障害が起きても検知が遅れ、深夜に手動でコンソールを確認することが常態化します。SREとして監視設計の経験を積む上でも、CloudWatchを体系的に使いこなせるかどうかは大きな差になります。
本記事では、SREが優先すべきCloudWatchの5つの機能を整理し、それぞれの設定指針とSLI/SLOへの接続方法まで解説します。
この記事でわかること
– CloudWatchの全体像と5つの主要機能の役割
– SREが最初に手をつけるべき機能とその順番
– メトリクス・アラーム・Logsの実務的な設定指針
– CloudWatch Application SignalsでSLOを管理する方法
AWSの基本的な操作経験があり、SRE・インフラエンジニアとして監視設計を学びたい方を対象としています。
CloudWatchとは?AWS監視の中心にある理由
Amazon CloudWatchは、AWSが提供するフルマネージドの監視・オブザーバビリティサービスです。EC2、RDS、ALBなどのAWSリソースからメトリクスやログを収集し、可視化・アラート・自動化を一元的に担います。
CloudWatchの位置づけ——AWSサービスとの連携全体像
CloudWatchはAWSの「神経系」とも言える存在で、ほぼすべてのAWSサービスと標準で統合されています。
graph LR A["AWSリソース (EC2 / RDS / ALB)"] --> B["メトリクス"] A --> C["Logs"] B --> D["アラーム"] B --> E["ダッシュボード"] C --> E D --> F["SNS / Lambda Auto Scaling"] B --> G["Application Signals (SLO管理)"]
独自アプリケーションからのカスタムメトリクスや、オンプレミスサーバーのログもCloudWatchエージェント経由で取り込めるため、ハイブリッド環境の統合監視基盤としても機能します。
CloudWatchでできる5つのこと
| 機能 | 役割 | SREでの主な用途 |
|---|---|---|
| メトリクス | 数値データの収集・保存 | CPU・レイテンシ・エラー率の監視 |
| アラーム | 閾値超過の検知・通知 | インシデント検知・自動スケール |
| Logs | ログの収集・検索・保管 | エラー調査・監査ログ管理 |
| ダッシュボード | メトリクス・ログの可視化 | チーム共有の運用ビュー |
| Application Signals | SLO管理・エラーバジェット | サービス信頼性の定量管理 |
CloudWatchを使わないとどうなるか
CloudWatchを適切に設定していない場合、障害の検知はユーザーからの問い合わせが起点になります。検知が遅れるほど影響範囲が広がり、復旧コストも増大します。また、SLO未設定の状態では「どの程度の障害が許容範囲か」をチームで合意できず、優先順位の判断が属人化します。
機能① メトリクス——SREが最初に見るべき数値
メトリクスはCloudWatchの最も基本的な要素です。AWSリソースが自動的に送信する 標準メトリクス と、アプリケーションから任意に送信できる カスタムメトリクス の2種類があります。
標準メトリクスとカスタムメトリクスの違い
標準メトリクス はEC2のCPU使用率やRDSのコネクション数など、AWSが自動で収集するものです。追加設定なしで利用でき、無料で取得できます(一部サービスを除く)。
カスタムメトリクス はアプリケーション固有の値(注文数・レスポンスタイムのパーセンタイル・キューの深さなど)を PutMetricData APIやCloudWatchエージェント経由で送信します。SLIの設計では、このカスタムメトリクスが核心になります。
SREが優先して監視すべきメトリクス一覧
SREの観点では、 ゴールデンシグナル(レイテンシ・トラフィック・エラー・サチュレーション)を優先して押さえます。
| リソース | メトリクス名 | ゴールデンシグナル |
|---|---|---|
| EC2 | CPUUtilization | サチュレーション |
| EC2 | StatusCheckFailed | エラー |
| ALB | TargetResponseTime | レイテンシ |
| ALB | HTTPCode_Target_5XX_Count | エラー |
| ALB | RequestCount | トラフィック |
| RDS | DatabaseConnections | サチュレーション |
| RDS | ReadLatency / WriteLatency | レイテンシ |
高解像度メトリクスとコストのトレードオフ
標準のメトリクス取得間隔は 1分 ですが、高解像度メトリクスを使うと 1秒〜10秒 間隔で取得できます。スパイク性の障害を見逃したくない場合に有効ですが、カスタムメトリクスとして送信するコストが発生します。本番環境では重要なエンドポイントのレイテンシのみ高解像度にするなど、コストと精度のバランスを取る設計が必要です。
機能② アラーム——閾値設計の考え方
アラームは収集したメトリクスを監視し、条件を満たしたときに通知やアクションを実行する機能です。設定が甘いとアラートが多発して疲弊し、設定が厳しすぎると検知が遅れます。
アラームの3状態
graph LR A["INSUFFICIENT_DATA (データ不足)"] -->|データ蓄積| B["OK (正常)"] B -->|閾値超過| C["ALARM (異常)"] C -->|閾値回復| B B -->|データ途絶| A
新規に作成したアラームは最初 INSUFFICIENT_DATA 状態になります。この状態を「問題なし」と誤解してそのまま放置するケースがあるため注意が必要です。評価期間(データポイント数)を適切に設定し、正常に OK 状態に遷移するまで確認することが重要です。
閾値の決め方——経験則ではなくSLOから逆算する
「CPU 80%超えたらアラート」という経験則ベースの閾値設定は、誤報とアラート疲れの原因になります。SREの考え方では、 SLO(サービスレベル目標)から逆算して閾値を設定 します。
例: 「月間稼働率 99.9%(月のダウンタイム 43分以内)」をSLOとする場合
– エラーバジェット消費速度を計算し、「このペースが続くとSLOを割る」タイミングでアラートを出す
– 単純な閾値ではなく 異常検知 や 予測アラーム の活用も検討する
SNS・Lambda・Auto Scalingとの連携パターン
| 連携先 | 用途 | 設定のポイント |
|---|---|---|
| Amazon SNS | メール・Slack通知 | トピックを環境(本番/検証)ごとに分ける |
| AWS Lambda | 自動復旧スクリプト実行 | 冪等性のある処理のみ自動化する |
| Auto Scaling | キャパシティの自動調整 | スケールインの閾値はスケールアウトより緩めに設定する |
機能③ Logs——ログ収集・検索・保管設計
CloudWatch Logsは、EC2・Lambda・ECSなどのログを一元的に収集・保管・検索できる機能です。アプリケーションのエラー調査から監査ログ管理まで幅広く使われます。
CloudWatch Logsの基本構造
| 概念 | 説明 | 例 |
|---|---|---|
| ロググループ | ログの論理的なまとまり | /aws/ec2/myapp |
| ログストリーム | 個別ログ発生源からの連続したログ | インスタンスID別のストリーム |
| ログイベント | 個々のログレコード | タイムスタンプ+メッセージ |
ロググループの保持期間はデフォルトで 無期限 です。コスト管理の観点から、本番ログは90日〜1年、デバッグログは7〜30日など、用途に応じて保持期間を設定することを推奨します。
CloudWatchエージェントのインストールと設定
EC2からシステムログ・アプリケーションログを収集するには、CloudWatchエージェントのインストールが必要です。
# エージェントのインストール(Amazon Linux 2)
sudo yum install amazon-cloudwatch-agent
# 設定ウィザードの起動
sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-config-wizard
# エージェントの起動
sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl \
-a fetch-config \
-m ec2 \
-c ssm:/AmazonCloudWatch-Config \
-s
設定ファイルは SSM Parameter Store に保存しておくと、複数インスタンスへの設定配布が容易になります。
Logs Insightsでよく使うクエリパターン集
CloudWatch Logs Insightsを使うと、大量のログをSQLライクなクエリで高速に検索できます。
# エラーログの件数を時系列で集計
fields @timestamp, @message
| filter @message like /ERROR/
| stats count(*) as errorCount by bin(5m)
| sort @timestamp desc
# レスポンスタイムの遅いリクエストを抽出
fields @timestamp, requestId, duration
| filter duration > 3000
| sort duration desc
| limit 20
# ステータスコード別のリクエスト数を集計
fields @timestamp, status
| stats count(*) as count by status
| sort count desc

機能④ ダッシュボード——チームで使える可視化設計
CloudWatchダッシュボードは、メトリクス・アラーム・ログを1つの画面に集約して可視化する機能です。個人の調査用途だけでなく、チーム全体の運用ビューとして設計することで、インシデント対応の速度が大きく向上します。
ダッシュボードの設計原則
ダッシュボードを作る前に「 誰が・何の目的で見るか 」を明確にします。
| 用途 | 対象者 | 含めるべき情報 |
|---|---|---|
| オンコール対応 | 当番エンジニア | アラーム状態・エラー率・レイテンシ |
| サービス定点観測 | チーム全員 | SLO達成率・リクエスト数・可用性 |
| コスト監視 | 管理者 | リソース使用率・Budgets連携 |
目的が混在したダッシュボードは情報が多すぎて逆に使いにくくなります。用途ごとにダッシュボードを分けることを推奨します。
よく使うウィジェットと配置パターン
| ウィジェット | 用途 | 配置のコツ |
|---|---|---|
| 折れ線グラフ | メトリクスの時系列変化 | 画面上部に配置し全体のトレンドを把握 |
| アラームステータス | 現在の異常有無 | 最も目立つ位置(左上)に配置 |
| 数値 | 現在値のスナップショット | レイテンシ・エラー率など重要指標を大きく表示 |
| ログクエリ | Logs Insightsの結果 | エラーログの件数などをリアルタイム表示 |
クロスアカウント・クロスリージョンダッシュボードの活用
複数のAWSアカウントやリージョンにまたがる環境では、 CloudWatchクロスアカウント可視化 を使うと、1つのダッシュボードに複数環境のメトリクスを集約できます。本番・検証・開発環境を1画面で比較する際に特に効果的です。設定は監視対象アカウントで共有設定を有効にするだけで完了します。
機能⑤ Application Signals(SLO)——SREの本丸
CloudWatch Application Signalsは2024年にGAになった機能で、SLO(サービスレベル目標)の設定・追跡・アラートをAWSコンソール上で完結できます。従来は独自実装が必要だったSLO管理が、標準機能として提供されるようになりました。
SLI・SLO・エラーバジェットの概念整理
graph TD A["SLA (契約上の保証)"] --> B["SLO (内部の目標値) 例: 可用性 99.9%"] B --> C["SLI (測定する指標) 例: 成功リクエスト率"] B --> D["エラーバジェット (許容できる失敗量) 例: 月43分のダウン"] D --> E["エラーバジェット消費率 (アラートの根拠)"]
- SLI(Service Level Indicator): 信頼性を測定する具体的な指標。可用性・レイテンシ・エラー率など
- SLO(Service Level Objective): SLIに対して設定する目標値。「99.9%のリクエストを200ms以内に返す」など
- エラーバジェット: SLOから逆算した「許容できる失敗量」。バジェットが残っているうちは機能開発を優先し、枯渇しそうになったら安定化にシフトする判断基準になります
CloudWatch Application SignalsでSLOを設定する手順
1. CloudWatchコンソール → 左メニュー「Application Signals」→「サービスレベル目標」
2. 「SLOを作成」をクリック
3. SLIを選択:
- サービスとオペレーション(自動検出されたエンドポイント)
- または任意のCloudWatchメトリクス・メトリクス式
4. SLOの目標値を設定:
- 達成率の目標: 例)99.9%
- 評価期間: ローリング(直近N日)またはカレンダー(月次)
5. アラームを作成:
- SLO未達アラーム(即時通知用)
- エラーバジェット消費率アラーム(早期警戒用)
SLOアラームとエラーバジェット消費率の監視
単純な「SLO未達アラーム」だけでは検知が遅れます。SREの実務では エラーバジェット消費率 を監視することで、問題を早期に察知できます。
| アラームの種類 | 閾値の例 | 意味 |
|---|---|---|
| バーンレートアラーム(高速) | 消費率 14.4倍(1時間) | 今のペースが続くと1時間でバジェットを使い切る |
| バーンレートアラーム(低速) | 消費率 6倍(6時間) | 緩やかだが確実にバジェットを消費している |
| SLO未達アラーム | 達成率 < 目標値 | 評価期間内でSLOをすでに割っている |
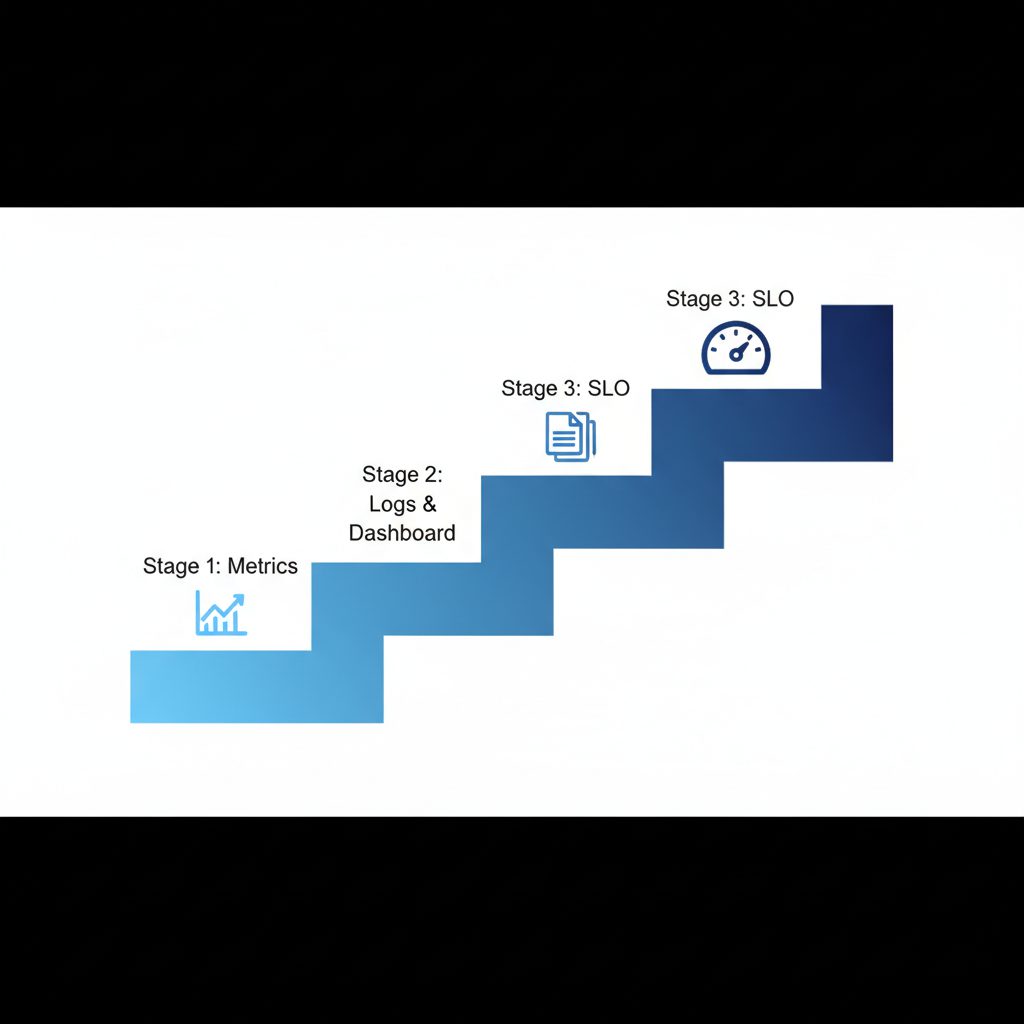
5機能の優先順位と導入ロードマップ
CloudWatchの5機能をすべて一度に整備するのは現実的ではありません。以下のロードマップを参考に段階的に導入することを推奨します。
ステージ別おすすめ設定順序
graph LR A["Stage 1 入門 メトリクス確認 基本アラーム"] --> B["Stage 2 中級 Logs収集 ダッシュボード作成"] B --> C["Stage 3 上級 SLO設定 エラーバジェット管理"]
Stage 1(入門): まず「見える化」する
– ゴールデンシグナル(レイテンシ・エラー率・トラフィック・サチュレーション)のメトリクスを確認
– 明らかな異常を検知する基本アラームを設定(CPU 90%超、5xxエラー急増など)
– 所要時間: 半日〜1日
Stage 2(中級): ログと可視化を整備する
– CloudWatchエージェントでアプリケーションログを収集
– Logs Insightsでエラー集計クエリを作成
– オンコール対応用ダッシュボードを作成
– 所要時間: 2〜3日
Stage 3(上級): SLOで信頼性を定量管理する
– Application SignalsでSLIを定義
– チームで合意したSLO目標値を設定
– バーンレートアラームを構成
– 所要時間: 1週間〜(SLO目標値の合意に時間がかかる場合が多い)
よくあるつまずきポイントと対処法
| つまずき | 原因 | 対処法 |
|---|---|---|
| アラートが多発して無視されるようになった | 閾値が低すぎる・評価期間が短すぎる | SLOベースで閾値を再設計し、評価期間を延ばす |
| ログが収集されない | エージェント未起動・IAMロール不足 | エージェントのステータス確認 + IAMポリシーに CloudWatchAgentServerPolicy を付与 |
| ダッシュボードが重くて使われない | ウィジェットが多すぎる | 1ダッシュボード最大10〜15ウィジェットを目安に絞る |
| SLO設定後にエラーバジェットがすぐ枯渇する | 目標値が高すぎる | 過去実績(直近30日の実測値)から現実的な目標値に調整する |
次に学ぶべきCloudWatch周辺サービス
CloudWatchを使いこなした後は、以下のサービスと組み合わせることでオブザーバビリティをさらに強化できます。
| サービス | 役割 | CloudWatchとの関係 |
|---|---|---|
| AWS X-Ray | 分散トレーシング | Logsと連携してリクエストの全経路を追跡 |
| Amazon Managed Grafana | 高度な可視化 | CloudWatchをデータソースとして利用 |
| AWS CloudTrail | 操作ログ・監査 | CloudWatch Logsに連携してアラート化 |
| Amazon OpenSearch | ログ分析 | 大規模ログの全文検索・集計 |
まとめ
本記事では、SREが優先すべきCloudWatchの5機能と導入順序を解説しました。
この記事のポイント
– CloudWatchはメトリクス・アラーム・Logs・ダッシュボード・Application Signalsの5機能で構成される
– まずゴールデンシグナルのメトリクス確認と基本アラームから始める
– アラームの閾値は経験則ではなく、SLOから逆算して設計する
– CloudWatch Application SignalsでSLO・エラーバジェット管理をコンソール上で完結できる
– Stage 1(見える化)→ Stage 2(ログ・ダッシュボード)→ Stage 3(SLO管理)の順で段階的に整備する
CloudWatchの設定を手を動かしながら学びたい方には、Udemyコース 「AWS×SRE入門」 で実践演習できます。本記事で解説したメトリクス設計・アラーム設定・SLO実装を、実際のAWS環境を使いながらステップバイステップで習得できます。
[Udemyコース「AWS×SRE入門」を見てみる]
まず1講義だけ無料で視聴できます。コースの内容を確認してから受講を判断いただけます。
関連記事
– SRE求人票から逆算|AWSエンジニアがSRE転職に必要なスキルと優先順位
– SREエンジニアのスキルセット|必須・推奨・差別化の3段階で解説
– SREの仕事って何をするの?1日の業務タイムラインとツール一覧

コメント