
SRE求人票を見るたびに、「プログラミング経験」という要件に不安を感じていませんか。
インフラ一筋でキャリアを積んできたエンジニアが、SRE転職で最初にぶつかる壁のひとつが「アプリケーション知識の壁」です。スタックトレースが読めない、OutOfMemoryErrorの意味がわからない、GCが何をしているか説明できない——この状態では、開発チームと対等に障害対応を行うことができません。
本記事では、SREとして必要な 「書ける力」ではなく「理解できる力」 にフォーカスし、インフラエンジニアが特につまずくプログラミング知識を体系的に解説します。読み終わる頃には、開発チームとの障害対応コミュニケーションに自信が持てるようになります。
この記事でわかること
– SRE求人でプログラミング知識が求められる理由と実際の要件レベル
– 「コードを書く力」と「アプリの動作を理解する力」の違い
– JavaのヒープとスタックおよびGC(ガベージコレクション)の仕組み
– スタックトレースの読み方と障害対応への活用
– スレッド・デッドロックの基礎知識とスレッドダンプの見方
– フレームワーク知識はどこまで必要かの判断基準
– 言語別の要求水準まとめ
この記事の対象読者
– インフラエンジニア歴2年以上でSRE転職を検討している方
– SRE求人のプログラミング要件に不安を感じている方
– 障害対応で開発チームと話が噛み合わないと感じている方
SRE求人でプログラミング知識が求められる理由
SRE求人票に見るプログラミング要件の実態
SRE求人票を複数社分析すると、プログラミング要件はおおむね以下のように分類できます。
| 区分 | 内容 | 必須/尚可 |
|---|---|---|
| スクリプト言語 | Python、Bash/Shell | 必須が多い |
| システム言語 | Go | 尚可が多い |
| アプリ言語 | Java、Ruby、PHP | 尚可が多い |
| アプリ知識 | Webアプリの動作原理・バックエンド構造の理解 | 暗黙的に必須 |
注目すべきは 「アプリ知識」 の欄です。Java や Ruby を「書ける」ことは尚可扱いでも、「Webアプリがどのように動くか理解している」ことは、多くの求人で暗黙的に必須とされています。
インフラエンジニアが直面するプログラミングの壁
インフラエンジニアが SRE に転向した際に最もつまずくのは、コードを書くことではなく アプリケーション目線でのトラブルシューティング です。
graph TD
A["障害発生
(レイテンシースパイク)"] --> B{"原因の切り分け"}
B -->|インフラ層| C["CPU・ネットワーク・
ディスクを確認
✅ インフラエンジニアが得意"]
B -->|アプリ層| D["GC・スタックトレース・
スレッドダンプを確認
⚠️ SREとして必要な知識"]
D --> E["開発チームと連携し
根本原因を特定"]
「インフラには問題ない」と判断した後、アプリ側の問題を開発チームと協力して追うのが SRE の仕事です。この時点でアプリ動作の知識がないと、開発チームの言葉が理解できず、障害対応が長引きます。
「書ける」は不要、「理解できる」が必須という整理
SRE に転向する上で必要なプログラミング力は、以下の表で整理できます。
| スキル | SREとして必要か |
|---|---|
| フレームワークで機能を開発する | 不要 |
| コードの動作をトレースできる | 必要 |
| スタックトレースを読み解ける | 必須 |
| GC・メモリ管理の仕組みを説明できる | 必須 |
| Python/Bash で自動化スクリプトを書ける | 必須 |
つまり、「アプリケーションの動作原理を知っている」 ことが重要であり、コードを書く力は優先度が下がります。
Javaのメモリ構造:ヒープとスタックを理解する
インフラ視点とアプリ視点のメモリ管理の違い
インフラエンジニアが「メモリ」を見る場合、top や free コマンドで物理メモリの使用量を確認するのが一般的です。しかし、アプリケーションの障害を追う際は JVM(Java仮想マシン)の内部メモリ構造 を把握している必要があります。
| 視点 | 確認手段 | 対象 |
|---|---|---|
| インフラ視点 | top / free / CloudWatch メモリメトリクス | OSレベルの物理メモリ使用量 |
| アプリ視点 | JVM ヒープ使用量 / GC ログ | JVMが管理するオブジェクトの生存状態 |
OSのメモリに問題がなくても、JVMのヒープが枯渇すれば OutOfMemoryError が発生してアプリが落ちます。これがインフラ視点だけでは追えない障害の典型例です。
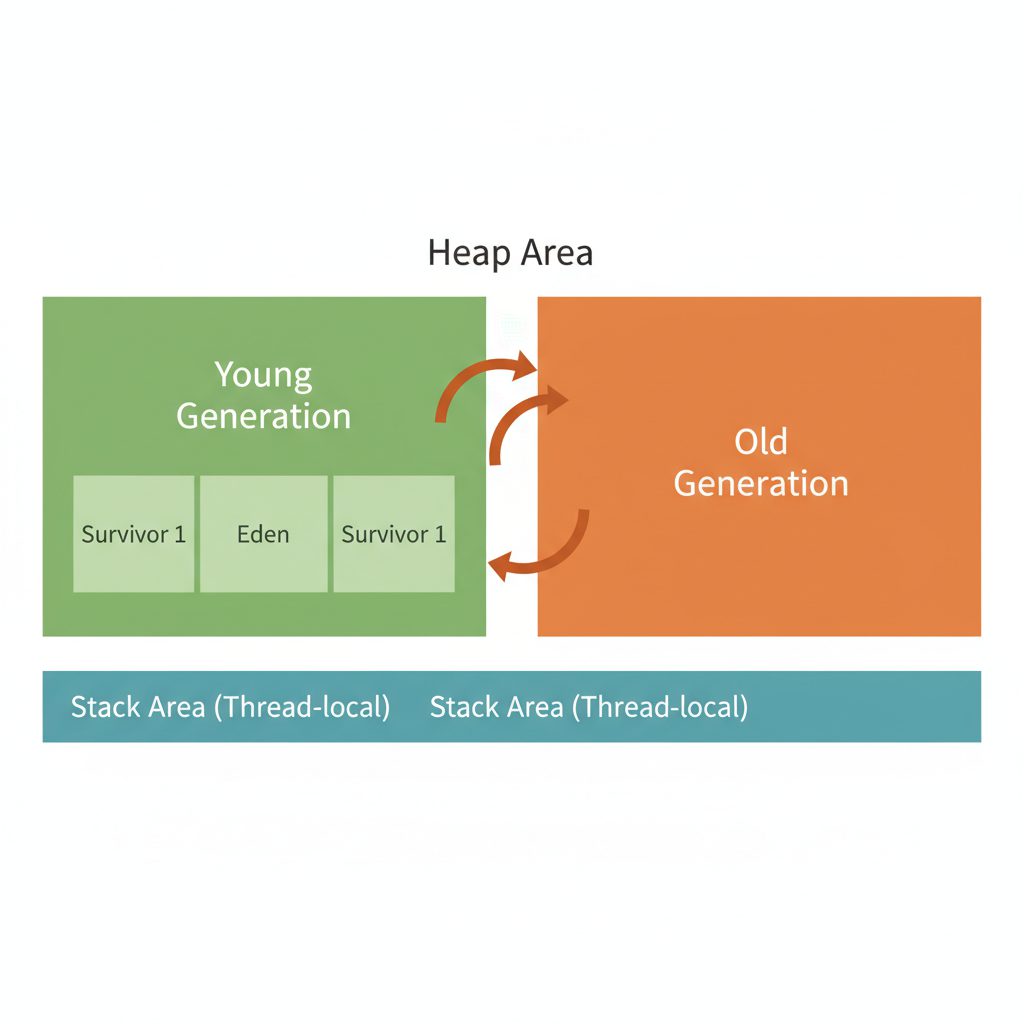
ヒープ領域とスタック領域の役割
Javaのメモリは大きく ヒープ領域 と スタック領域 に分かれます。
graph TD
A["JVMメモリ"] --> B["ヒープ領域(Heap)
オブジェクトを格納
GCが管理"]
A --> C["スタック領域(Stack)
スレッドごとに確保
メソッドの呼び出し履歴を保持"]
B --> D["Young世代
(Eden + Survivor×2)
新しいオブジェクト"]
B --> E["Old世代
長命なオブジェクト
Full GCの対象"]
ヒープ領域 は、new キーワードで生成されたオブジェクトが格納される場所です。GC(ガベージコレクション)によって不要なオブジェクトが定期的に削除されます。
スタック領域 は、メソッドの呼び出し履歴(コールスタック)を保持します。スタックトレースに表示されるのは、このスタック領域の情報です。
OutOfMemoryErrorの正体と原因特定
OutOfMemoryError は、ヒープ領域が枯渇した際に発生します。
java.lang.OutOfMemoryError: Java heap space
この場合の確認ポイントは以下の通りです。
- ヒープ使用量の推移:CloudWatch の JVM ヒープメトリクスやアプリケーションのメトリクスで確認
- GC の頻度と所要時間:GC ログで Full GC が頻発していないか確認
- メモリリークの有無:ヒープ使用量が GC 後も減らない場合はメモリリークを疑う
ガベージコレクション(GC)の仕組みとSREへの影響
GCとは何か:Minor GCとFull GC
GC とは、ヒープ領域の不要なオブジェクトを自動的に回収する仕組みです。インフラエンジニアが知っておくべきは、GC には Minor GC と Full GC の2種類があり、それぞれ挙動が大きく異なる点です。
| 種類 | トリガー | 対象領域 | 所要時間 | アプリへの影響 |
|---|---|---|---|---|
| Minor GC | Young世代(Eden)が満杯 | Young世代のみ | 数ミリ秒 | 軽微 |
| Full GC | Old世代が枯渇 | ヒープ全体 | 数秒〜数十秒 | 大きい(STW発生) |
Stop the World(STW)がSLOに与えるインパクト
Full GC の際に発生する STW(Stop the World) は、GC 実行中にアプリケーションのスレッドをすべて停止させる現象です。
graph TD
A["Old世代のヒープが枯渇"] --> B["Full GC 開始"]
B --> C["Stop the World
全スレッド停止
数秒〜数十秒"]
C --> D["ヒープの不要オブジェクトを回収"]
D --> E["GC 完了・スレッド再開"]
C --> F["この間、リクエストが処理されない
→ レイテンシースパイク
→ タイムアウト多発
→ SLO 違反の可能性"]
Full GC が頻発するシステムでは、SLO で設定したレイテンシー閾値を定期的に超えるという問題が起きます。CloudWatch メトリクスでレイテンシーが定期的にスパイクしている場合、GC が原因である可能性を必ずチェックしてください。
GCアルゴリズムの種類と選択基準
現在の Java 環境では、以下の GC アルゴリズムが主に使われています。
| アルゴリズム | 特徴 | 主な用途 |
|---|---|---|
| Serial GC | シングルスレッドで GC。小規模環境向け | 小規模バッチ |
| Parallel GC | マルチスレッドで GC。スループット重視 | Java 8 までのデフォルト |
| G1GC | ヒープをリージョン分割。停止時間を短縮 | Java 9 以降のデフォルト |
| ZGC | 低レイテンシー特化。STW がほぼゼロ | 高トラフィックシステム |
SRE として重要なのは、担当するシステムが どの GC を使っているか を把握し、GC ログを読めるようにしておくことです。
スタックトレースの読み方
スタックトレースとは何か
スタックトレースとは、エラーが発生した時点でのメソッド呼び出し履歴をテキスト形式で出力したものです。アプリケーションのエラーログに必ず含まれており、障害の根本原因を特定するための最重要情報です。
インフラエンジニアにとって馴染みが薄い理由は、インフラ障害ではスタックトレースが出ないから です。OS のエラーログや CloudWatch アラームは見慣れていても、Java のスタックトレースを読む機会がなかった方が多いはずです。
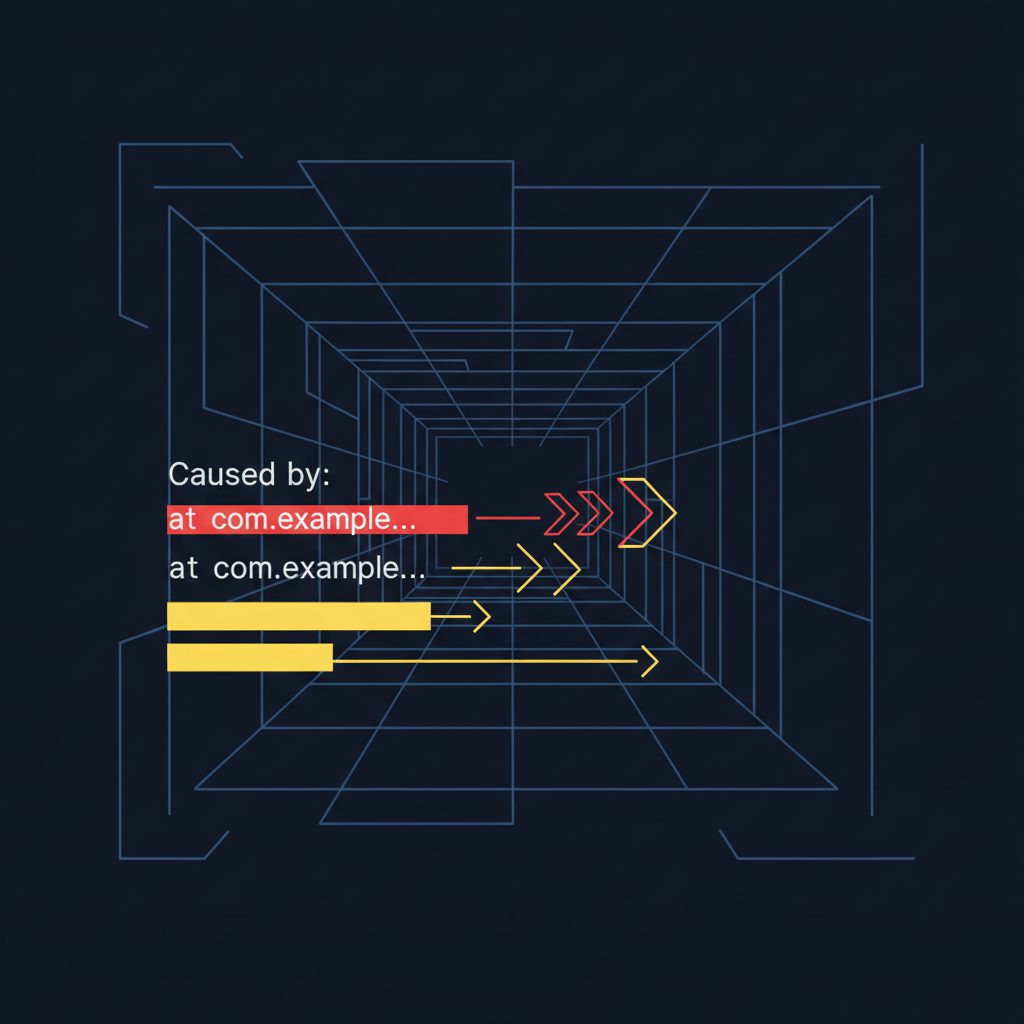
「Caused by:」から始める読み解き方
スタックトレースには独特の読み順があります。上から読まない のがポイントです。
Exception in thread "main" java.lang.RuntimeException: DB接続に失敗しました
at com.example.service.UserService.findById(UserService.java:42)
at com.example.controller.UserController.getUser(UserController.java:28)
at sun.reflect.NativeMethodAccessorImpl.invoke0(...)
...
Caused by: java.sql.SQLException: Connection refused
at com.mysql.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:2158)
at com.example.repository.UserRepository.getConnection(UserRepository.java:65)
... 5 more
読むべき順序:
Caused by:の行を探す(これが根本原因)Caused by:の直下にあるat com.example...の行を探す(自分たちのコード内の発生箇所)- 最初の例外メッセージを確認する(エラーの全体像)
上の例では、根本原因は java.sql.SQLException: Connection refused(DB への接続拒否)です。UserService や UserController は障害の発生箇所ではなく、エラーが伝播した経路です。
実際の読み解き手順
障害対応でスタックトレースを受け取った場合の手順をまとめます。
Caused by:を探し、例外クラス名とメッセージを確認するCaused by:直下のat行から、自社コード(com.example.*など)のパッケージを探す- そのクラス名・メソッド名・行番号を開発チームに伝える
- 例外クラスを検索して意味を確認する(
NullPointerException、SQLException、TimeoutExceptionなど)
「スタックトレースが読める」だけで、開発チームとの障害対応コミュニケーションが格段にスムーズになります。
スレッドの基礎知識:デッドロックとスレッドダンプ
マルチスレッドとは何か
Java のアプリケーションは、複数のスレッドが並行して動作するマルチスレッド環境で実行されます。Webアプリケーションでは、HTTP リクエストごとにスレッドが割り当てられるのが一般的です。
SRE として重要なのは、スレッドプールの枯渇 が障害として現れる点です。スレッドプールが上限に達すると、新しいリクエストは処理を待つか、タイムアウトエラーになります。
デッドロックが起きるメカニズム
デッドロックは、複数のスレッドが互いに相手のリソース解放を待ち続け、処理が止まってしまう状態です。
graph TD
A["スレッドA
ロックAを保持"] -->|"ロックBを要求"| B["待機中(ロックBはBが保持)"]
C["スレッドB
ロックBを保持"] -->|"ロックAを要求"| D["待機中(ロックAはAが保持)"]
B -.->|"永遠に解放されない"| C
D -.->|"永遠に解放されない"| A
デッドロックが発生すると、該当スレッドが BLOCKED 状態のまま CPU を使わずに停止します。CPU 使用率は低いのにアプリが応答しないという現象が起きた場合、デッドロックを疑ってください。
スレッドダンプの読み方基礎
スレッドダンプは、JVM 内の全スレッドの状態をスナップショットとして出力したものです。
"http-nio-8080-exec-1" #25 daemon prio=5 os_prio=0 tid=0x... nid=0x... waiting for monitor entry
java.lang.Thread.State: BLOCKED (on object monitor)
at com.example.OrderService.createOrder(OrderService.java:78)
- waiting to lock <0x...> (a com.example.Lock)
- locked <0x...> (a com.example.OtherLock)
スレッドの状態は以下の通りです。
| 状態 | 意味 | 障害との関係 |
|---|---|---|
| RUNNABLE | 実行中または実行可能 | 正常 |
| BLOCKED | ロック待ちで停止中 | デッドロックやコンテンション疑い |
| WAITING | 特定イベント待ちで停止中 | 正常な待機またはデッドロック疑い |
| TIMED_WAITING | タイムアウト付き待機 | 正常な待機(sleep等) |
BLOCKED 状態のスレッドが多数存在する場合は、デッドロックまたはロックの競合が発生している可能性があります。開発チームに「スレッドダンプを取得して BLOCKED なスレッドを確認してほしい」と伝えられるだけで、障害対応のスピードが変わります。
フレームワーク知識はどこまで必要か
特定フレームワークの書き方は不要
Spring Boot、Django、Rails などの Web フレームワークのコードを書ける必要はありません。SRE の役割はアプリケーション機能の開発ではなく、サービスの信頼性を保つことです。SRE の求人票でフレームワーク名が必須要件に入ることはほぼなく、「尚可」止まりです。
押さえておきたいフレームワークの「概念」
ただし、フレームワークが 何をやっているか の概念は知っておく必要があります。
| 概念 | なぜSREに必要か |
|---|---|
| DI(依存性注入)・Bean管理 | 起動失敗ログに出る Bean初期化エラー の意味がわかる |
| ORMのN+1問題 | DBスロークエリの根本原因がORM側にあることを切り分けられる |
| コネクションプール | DB接続数枯渇時にアプリ側設定(HikariCP等)を確認できる |
| ミドルウェア・フィルターチェーン | リクエストがどこで止まっているかをログから追える |
| セッション管理 | セッション切れやメモリリークを「アプリの問題」として切り分けられる |
障害対応での実際の立ち回り
SRE としてのフレームワーク知識の使い方は、「この障害はフレームワーク層の問題か、アプリロジック層の問題か、インフラ層の問題か」を切り分けることです。
切り分けができれば、開発チームに適切な情報を渡せます。全部を自分で解決する必要はありません。担当サービスで使われているフレームワーク名(Spring Boot なのか Django なのか)くらいは把握しておき、コードを読む必要が出た場合は開発者と一緒に確認するスタンスで十分です。

言語別の要求水準まとめ
SREとして求められる言語スキルの全体像
SRE として求められる言語スキルを言語ごとに整理します。
| 言語 | 求められるレベル | 優先度 |
|---|---|---|
| Bash/Shell | 既存スクリプトの修正・新規作成ができる | ★★★ 最優先 |
| Python | boto3 で AWS 操作、簡単な自動化・データ加工ができる | ★★★ 最優先 |
| Go | コードを読める。書けると強い(SRE系ツールの多くがGo製) | ★★ 推奨 |
| Java | 書けなくてよい。読めて GC・スレッドを理解していることが重要 | ★★ 推奨 |
優先的に学ぶべき言語と学習ポイント
まず身につけるべきは Bash と Python です。
Bash は運用スクリプトのほぼすべてに登場します。既存スクリプトを読んで意図を把握し、軽微な修正ができれば十分です。Python は boto3 を使った AWS 操作自動化と、ログ解析・アラート通知などのスクリプト作成が主な用途です。
Java の知識はコードを書く必要はなく、本記事で解説した GC・メモリ・スタックトレース・スレッドの概念を理解していれば実務で機能します。
まとめ
インフラエンジニアがSREを目指す際のプログラミング知識について、押さえるべきポイントをまとめます。
この記事のポイント
– SRE に必要なのは「コードを書く力」ではなく「アプリケーションの動作を理解する力」
– JavaのGCは Minor GC(短時間・軽微) と Full GC(STW発生・SLO影響大) を区別して理解する
– スタックトレースは 「Caused by:」から読む ことで根本原因に最短で辿り着ける
– BLOCKED 状態のスレッドが多い場合は デッドロックまたはロックの競合 を疑う
– フレームワークの 書き方 は不要だが、DI・ORM・コネクションプールの 概念 は必要
– まず Bash と Python を優先的に習得し、Java はGC・スレッドの理解に集中する
スタックトレースが読める+GCの概念を理解している だけで、開発チームとの障害対応コミュニケーションが格段に変わります。「インフラしかわからない」から「アプリ側の問題も切り分けられる」へのシフトは、SRE としての価値を大きく高めます。
AWS×SREのスキルを体系的に学ぶなら
インフラエンジニアが SRE にキャリアチェンジする際の全体像——監視設計・SLO設計・インシデント対応・コスト最適化まで——を体系的に学べる Udemy コースを公開しています。
プログラミング知識に加えて AWS 運用設計のスキルを固めることで、SRE 転職の準備が格段にスムーズになります。
[現場のSREが教える AWS運用設計入門〜監視・障害対応・SLO設計をゼロから学ぶ〜(Udemy)]
関連記事
– SREエンジニアとは?インフラエンジニアとの違いを現役が解説
– SRE求人票から逆算|必要なスキルと優先順位
– SREエンジニアのスキルセット|必須・推奨・差別化の3段階で解説

コメント