CloudWatchでアラームを設定しているのに、「どの障害が本当に重要か」「どこまで対応すれば十分か」の判断基準が曖昧なまま運用していませんか?
属人的な判断で優先度を決め続けると、軽微なアラートに深夜対応し、本当に重要なインシデントを見落とすリスクが高まります。SREとしてキャリアアップを目指す場合、SLI/SLOの設計と運用は避けて通れないスキルです。
本記事では、CloudWatchを使ってSLI/SLOを設計・設定する方法を、CloudWatch Application Signalsによる実装手順とエラーバジェット管理まで含めて解説します。
この記事でわかること
- SLI・SLO・SLAの違いと実務での使い分け
- CloudWatch Application SignalsでSLOを設定する手順
- エラーバジェットとバーンレートアラームの設定方法
- SLO目標値の決め方と設計のベストプラクティス
前提条件
- AWSアカウントがある
- CloudWatchの基本操作を理解している(CloudWatch入門記事 参照)
- JavaやPython等で書かれたアプリケーションがECS・Lambda・EC2上で動作している
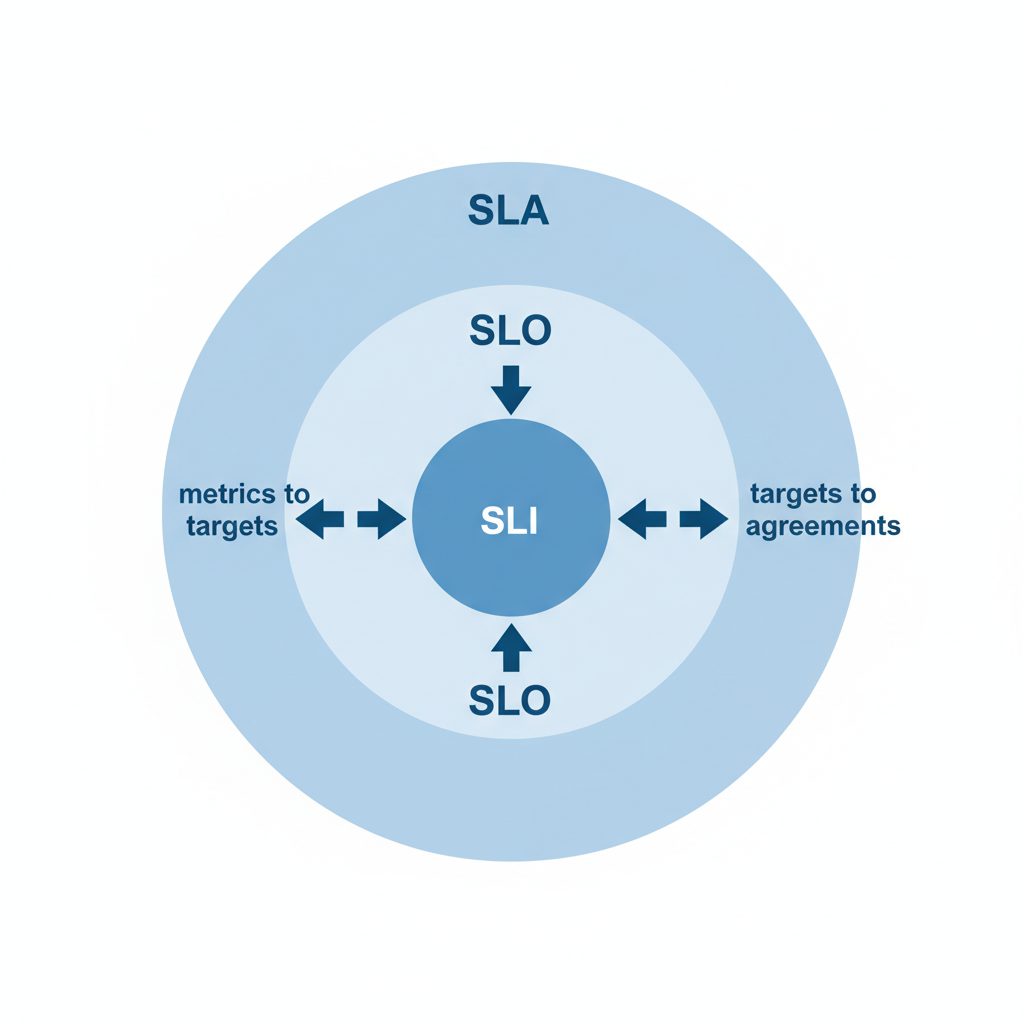
SLI・SLO・SLAとは何か
SLI/SLOは「サービスの信頼性をどう測り、どこまで維持するか」を定量化する仕組みです。まず3つの概念を整理します。
SLI(Service Level Indicator):何を測るか
SLIはサービスレベルを表す 定量的な指標 です。「現在のサービスが、どのくらいの品質で動いているか」を数値で示します。
代表的なSLIの例:
| SLIの種類 | 測定内容 | 計算式の例 |
|---|---|---|
| 可用性(Availability) | 正常レスポンスの割合 | 成功リクエスト数 ÷ 全リクエスト数 |
| レイテンシー(Latency) | レスポンス時間の分布 | P99レイテンシーが500ms以下の割合 |
| スループット(Throughput) | 単位時間あたりの処理量 | 1秒あたりのリクエスト数 |
| エラー率(Error Rate) | エラーレスポンスの割合 | 5xxエラー数 ÷ 全リクエスト数 |
実務では 可用性とレイテンシー を最初のSLIに選ぶことが多いです。測定が容易で、ユーザー体験への影響がわかりやすいためです。
SLO(Service Level Objective):どこまで維持するか
SLOは「SLIをどのレベルで維持するか」という 目標値 です。社内でチームが合意した基準として機能します。
例:
– 可用性SLO:「1ヶ月間で99.9%以上の可用性を維持する」
– レイテンシーSLO:「P99レイテンシーが500ms以下である割合を95%以上に保つ」
SLOを設定すると、チームは「この障害はSLO違反を引き起こすか」という基準で優先度を判断できるようになります。深夜対応が本当に必要かどうかの判断もSLOを根拠にできます。
SLA・SLO・SLIの違い
混同しやすい3つの概念を整理します。
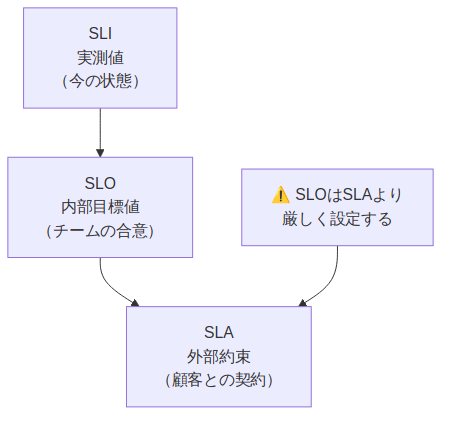
SLAはSLOより緩く設定する のが鉄則です。SLOを99.9%に設定していれば、SLAは99.5%程度にします。SLO違反が検知されたときに、SLA違反になる前に修正する余裕が生まれます。
CloudWatchでSLI/SLOを実装する2つのアプローチ
CloudWatchでSLI/SLOを管理する方法は大きく2つあります。
アプローチ①:CloudWatch Application Signals(推奨)
2024年にGAとなった CloudWatch Application Signals は、SLO管理に特化した機能です。アプリケーションのトレースデータからSLIを自動収集し、SLOとエラーバジェットをダッシュボードで可視化できます。
メリット:
– SLIの手動設計が不要(自動でLatency・Availabilityを収集)
– エラーバジェットとバーンレートをリアルタイム表示
– 推奨SLOの提案機能(過去30日のデータから自動算出)
対応サービス:
ECS(Fargate/EC2)、Lambda、EC2(Java・Python・.NET・Node.js)
アプローチ②:CloudWatch メトリクス + カスタム計算
Application Signalsが対応していないサービス(Aurora等)や、独自のSLI定義が必要な場合に使います。
- ALBのアクセスログをS3に保存 → Athenaでクエリ → SLIを計算
- CloudWatch Logs Insightsでエラー率を集計(Logs Insightsクエリ記事 参照)
- 計算結果をCloudWatchカスタムメトリクスとして送信
どちらを選ぶか:
Application Signalsに対応したスタック(ECS/Lambda/EC2)なら Application Signalsが最短経路 です。まずApplication Signalsで始め、細かいカスタマイズが必要になったらカスタムメトリクスを追加する流れを推奨します。
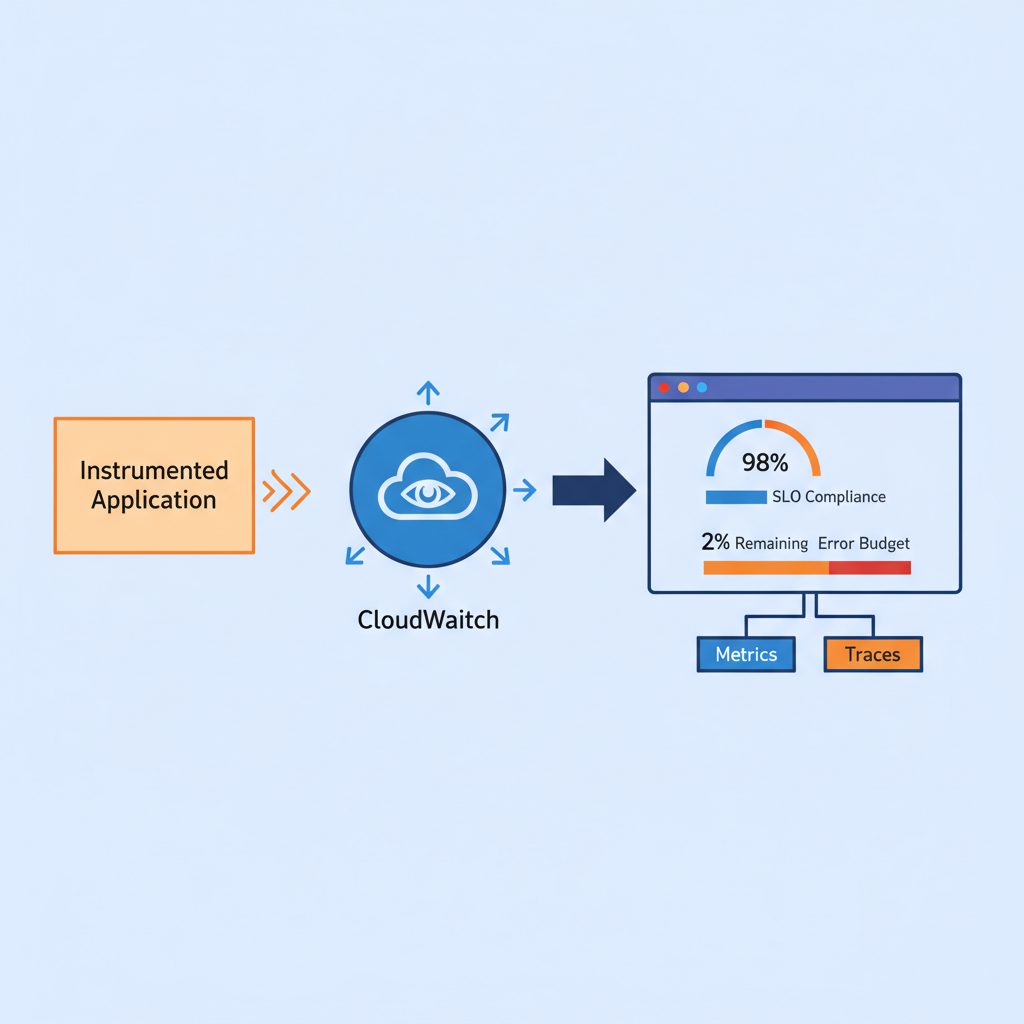
CloudWatch Application SignalsでSLOを設定する手順
Step 1:Application Signalsを有効化する
AWSコンソールの CloudWatch > Application Signals > サービス を開き、「Application Signalsを開始する」ボタンをクリックします。
有効化後、アプリケーションにAWS Distro for OpenTelemetry(ADOT)エージェントを導入します。ECS Fargateの場合、タスク定義のサイドカーとして追加します。
{
"name": "aws-otel-collector",
"image": "public.ecr.aws/aws-observability/aws-otel-collector:latest",
"environment": [
{
"name": "AOT_CONFIG_CONTENT",
"value": "extensions:\n health_check:\nreceivers:\n otlp:\n protocols:\n grpc:\n endpoint: 0.0.0.0:4317\nexporters:\n awsxray:\n awsemf:\nservice:\n pipelines:\n traces:\n receivers: [otlp]\n exporters: [awsxray]\n metrics:\n receivers: [otlp]\n exporters: [awsemf]"
}
]
}
エージェントが起動するとCloudWatchがトレースを収集し始め、Application Signals > サービス 画面にサービス一覧が表示されます。
Step 2:SLIの指標を選択する
CloudWatch > Application Signals > SLO を開き、「SLOを作成する」をクリックします。
- SLOの種類を選択:「可用性(Availability)」または「レイテンシー(Latency)」
- 対象サービスとオペレーションを選択:Application Signalsが自動検出したAPIエンドポイントが一覧表示される
可用性SLI の場合:
– 成功の定義:HTTPステータス2xx・3xxのレスポンス
– 測定単位:リクエスト成功率(%)
レイテンシーSLI の場合:
– パーセンタイル:P50・P90・P99から選択
– 閾値:「500ms以下」のように指定
初めてSLOを設定する場合は、「推奨SLOを表示」ボタンをクリックすると、過去30日間のデータを元にした目標値の提案が表示されます。
Step 3:SLOの目標値と評価期間を設定する
| 設定項目 | 説明 | 推奨値(初回) |
|---|---|---|
| SLO目標値 | 維持したい達成率 | 99.0〜99.9% |
| 評価期間 | ローリング期間 | 30日 |
| 間隔 | 測定の粒度 | 1分 |
評価期間の選択:
– ローリング期間(推奨):常に直近30日のデータで評価。運用開始直後から使えます
– カレンダー期間:月初めにリセット。月次レポートを出す場合に向いています
SLO名と説明を入力して「作成」をクリックすると、SLOダッシュボードに達成率とエラーバジェットが表示されます。
エラーバジェットとバーンレートアラームの活用
エラーバジェットとは
エラーバジェットは「SLOを下回ることが許容される余裕」です。
計算式:
エラーバジェット(%) = 100% − SLO目標値
例:SLO = 99.9% の場合
エラーバジェット = 0.1%(30日間で約43.2分)
エラーバジェットが残っている間は、新機能リリースや変更を積極的に行えます。エラーバジェットを消費しすぎた場合は、リリースを凍結して信頼性改善に集中します。この判断基準が明確になることが、SLO導入の最大のメリットです。
バーンレートアラームの設定方法
バーンレート とは、エラーバジェットを消費する速度です。バーンレート1.0 = 計画通りのペースで消費していることを意味します。
バーンレートアラームを設定すると、「このペースで障害が続くとエラーバジェットが枯渇する」ことを事前に検知できます。
Application Signalsでのバーンレートアラーム設定手順:
- SLO詳細画面を開き、「アラームを作成」をクリック
- アラームタイプで「バーンレートアラーム」を選択
- 以下の設定を入力:
| 項目 | 設定例 | 説明 |
|---|---|---|
| バーンレート閾値 | 14.4 | 1時間でエラーバジェットの5%を消費するペース |
| 評価期間 | 5分 | アラームを評価する間隔 |
| データポイント数 | 1/1 | 1回でも閾値超えたらアラート |
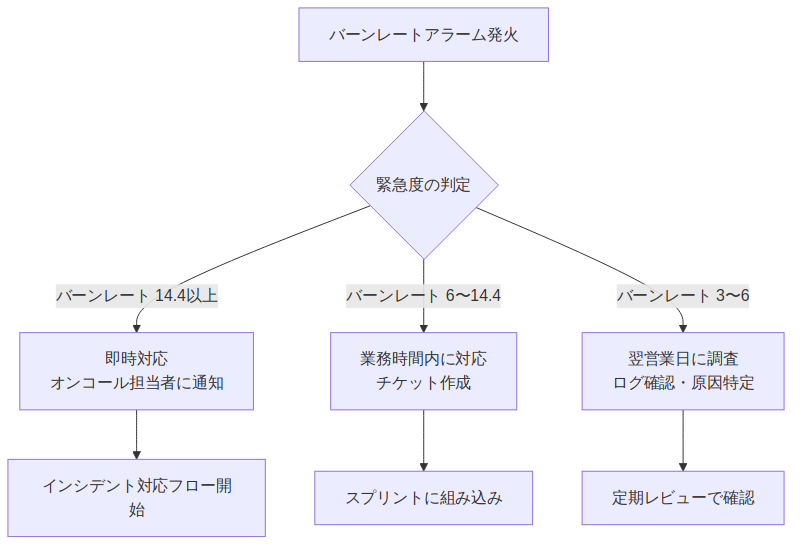
バーンレートと緊急度の目安:
| バーンレート | エラーバジェット枯渇まで | 対応レベル |
|---|---|---|
| 14.4以上 | 約1時間 | 即時対応(PagerDuty等) |
| 6以上 | 約2.5時間 | 業務時間中に対応 |
| 3以上 | 約5時間 | 翌営業日中に対応 |
| 1以下 | 30日以上 | 定期的な確認でOK |
# バーンレートの計算式
バーンレート = 現在のエラー率 ÷ エラーバジェット率
例:SLO = 99.9%(エラーバジェット = 0.1%)
現在のエラー率が1.0%の場合:
バーンレート = 1.0% ÷ 0.1% = 10
→ 約3時間でエラーバジェット枯渇
SLI/SLO設計のベストプラクティス
何をSLIに選ぶか
SLIは ユーザー体験に直結する指標 を選びます。内部的な指標(CPU使用率・メモリ使用率)をSLIにしても、ユーザーへの影響を正確に測れません。
SLIとして適切な指標:
– APIの成功率(HTTPステータスコードベース)
– レスポンスタイムのパーセンタイル(P90・P99)
– トランザクション完了率(決済成功率など)
SLIとして避けるべき指標:
– CPU使用率・メモリ使用率(リソース指標は原因であり結果ではない)
– 内部キューの深さ(ユーザー影響と直結しにくい)
– すべてのAPIをひとまとめにした集計値(問題のあるAPIが埋もれる)
SLO目標値の決め方
初めてSLOを設定する場合、過去の実績値より少し低い値から始めることを推奨します。
推奨アプローチ:
1. 過去30日の実績値を確認(Application Signalsの「推奨SLO」機能を活用)
2. 実績値より0.1〜0.5ポイント低い値を初期SLOに設定
3. 3ヶ月運用して問題なければ引き上げる
例:過去30日の可用性実績が99.95%だった場合
→ 初期SLO = 99.9%(実績より0.05%低く設定)
SLO目標値の目安:
| サービス種別 | 可用性SLO | レイテンシーSLO |
|---|---|---|
| 社内ツール・管理画面 | 99.0% | P95 < 2秒 |
| エンドユーザー向けAPI | 99.9% | P99 < 500ms |
| 決済・金融系API | 99.95%以上 | P99 < 300ms |
SLO違反時のアクション設計
SLOを設定しても、違反時のアクションが未定義では機能しません。あらかじめ対応フローを決めておきます。
エラーバジェットが残り20%を切った場合は、チームでリリース凍結を議論します。この判断をSLOという客観的な数値に基づいて行えることが、SRE文化の核心です。
まとめ
本記事のポイントを整理します。
- SLI はサービス品質の実測値。可用性・レイテンシーから始めるのが実用的
- SLO はSLIの内部目標値。チームの判断基準として機能する
- CloudWatch Application Signals を使えば、SLI収集とSLOダッシュボードを最短で構築できる
- エラーバジェット は変更推進と信頼性維持のバランスを取るための指標
- バーンレートアラーム で「SLO違反に向かっている」ことを事前に検知できる
SLI/SLOの考え方は、本記事で紹介したCloudWatch Application Signalsの設定と組み合わせることで、実務で即使えるスキルになります。
P3シリーズのこれまでの記事(CloudWatch入門 / アラーム設定 / CloudWatch Logs / Logs Insightsクエリ)と合わせて読むことで、CloudWatchを使った監視設計の全体像を理解できます。
CloudWatch×SRE監視設計を体系的に学ぶ
SLI/SLO設計・CloudWatch設定・アラーム設計・インシデント対応フローをひとつながりで学びたい方は、Udemyコース 「AWS×SRE入門〜CloudWatchで学ぶ監視設計の基礎〜」 をご確認ください。
CloudWatchの設定からSLOの考え方まで、実務に直結した内容をずんだもん解説で学べます。

コメント