「SREに転職したいけど、実際に何をしているのかイメージが湧かない」という疑問を持ったことはありませんか?
「信頼性を高める」「自動化する」という説明はよく見かけますが、それが毎日の業務にどう落とし込まれているのか、求人票を読むだけではなかなかわかりません。業務イメージが曖昧なままでは、転職面接で「SREとして何をしたいですか?」と聞かれたときに答えに詰まってしまいます。
本記事では、SREエンジニアの1日の業務タイムラインを時系列で整理したうえで、現場でよく使われるツールをカテゴリ別に紹介します。読み終わる頃には、SREの仕事の流れと必要なツールの全体像が把握できます。
この記事でわかること
- SREエンジニアの仕事内容を一言で整理する方法
- 朝から夕方までの1日の業務タイムライン
- 監視・インシデント管理・自動化など用途別のツール一覧
- SREを目指すためのツール学習の優先順位
対象読者: SREへの転職・異動を検討しているインフラエンジニア・バックエンドエンジニアで、SREの日常業務のイメージをつかみたい方。
SREエンジニアの仕事内容を一言で言うと
「信頼性を維持・向上させる」が中心テーマ
SREの仕事を一言で表すなら、「システムが安定して動き続けるための仕組みを作り、維持すること」 です。
サービスが落ちないようにする、落ちたときに素早く復旧させる、同じ障害が二度と起きないように改善する——この3つのサイクルがSREの業務の根幹です。
GoogleがSREを定義した書籍『SRE サイトリライアビリティエンジニアリング』では、信頼性の目標を SLO(Service Level Objective) として数値化し、その達成に向けてエンジニアリングで取り組むことをSREの本質としています。
「なんとなく監視する」ではなく、「99.9%の可用性を目標に設定し、そのために何が必要かをエンジニアリングで解決する」という姿勢が求められます。
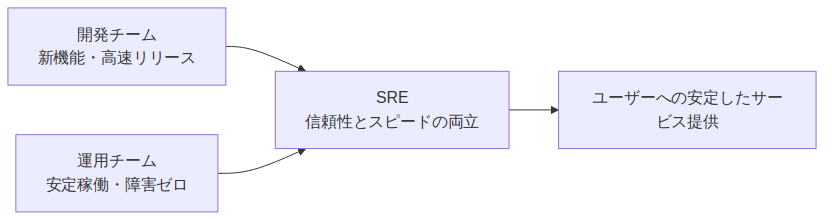
開発チームと運用チームの橋渡し役
SREが担う役割のもう一つの特徴は、開発と運用の間に立つ橋渡し役 である点です。
開発チームは「新機能を素早くリリースしたい」、運用チームは「システムを安定させたい」という異なる方向性を持ちます。この2つのゴールを両立させるために、SREはリリースプロセスの設計、デプロイ頻度のコントロール、障害時の対応フロー整備などを担います。
インフラエンジニアとの違い(再確認)
インフラエンジニアとSREの違いについては別記事で詳しく解説していますが、ここで簡単に整理しておきます。
| 項目 | インフラエンジニア | SRE |
|---|---|---|
| 主な関心 | インフラの構築・維持 | サービス信頼性の向上 |
| アプローチ | 手順・運用ルール | ソフトウェアエンジニアリング |
| 指標 | サーバー稼働率 | SLO・エラーバジェット |
| 自動化 | 補助的 | 中心的 |
インフラエンジニアとの違いをさらに詳しく知りたい方は「SREエンジニアとは?インフラエンジニアとの違いを解説」も合わせてご覧ください。

SREの1日の業務タイムライン
SREに決まった「1日のスケジュール」があるわけではありませんが、多くの現場で共通して見られる業務の流れを時系列で整理します。
午前 ─ 朝会・アラート確認・前日インシデントの振り返り
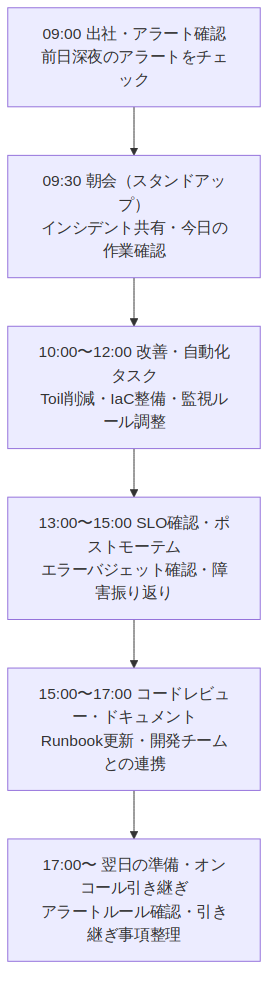
09:00〜09:30 アラート確認
出社後(またはリモートログイン後)最初にやることは、夜間に発生したアラートの確認 です。PagerDutyなどのインシデント管理ツールを開き、深夜に何か異常がなかったかを確認します。
オンコール担当者がいる場合、夜間インシデントの概要を引き継いで共有します。問題がなければそのまま朝会へ。問題があれば朝会前に一次対応を始めることもあります。
09:30〜10:00 朝会(スタンドアップ)
SREチームでは15〜30分程度の短い朝会を行うことが多いです。主な議題は以下の3点です。
- 前日・夜間に発生したインシデントの共有
- 今日対応するタスクの確認
- ブロッカー(作業を阻害している問題)の共有
Slackのスレッドで非同期に行うチームもあります。
午前〜午後 ─ 自動化・改善タスク・コードレビュー
朝会が終わると、SREの本質的な仕事である 「改善・自動化タスク」 に集中する時間になります。
SREの世界では、繰り返し手作業で行う単純作業を 「Toil(トイル)」 と呼び、これを減らすことが重要な仕事の一つとされています。Googleでは「SREの作業時間のうち50%以上をToil削減・システム改善に使うべき」という考え方を提唱しています。
具体的な作業例としては以下のようなものがあります。
- Terraform・Ansibleを使ったインフラのコード化(IaC)
- デプロイパイプラインの改善(GitHub Actionsなど)
- 監視アラートのチューニング(誤検知・過検知の削減)
- 不要なオンコール対応を減らすための自動復旧スクリプト作成
また、開発チームのPull Requestレビューに参加し、本番環境への影響を運用視点でチェックすることも担います。
午後 ─ SLO確認・ドキュメント整備・翌日の準備
13:00〜15:00 SLO確認・ポストモーテム
午後は週次・月次ペースで行うSLOの確認作業や、過去のインシデントの振り返り(ポストモーテム)に時間を使います。
SLO(Service Level Objective)とは、「このサービスは月間99.9%以上の可用性を保つ」といった目標値です。DatadogやCloudWatchのダッシュボードで現在の達成率を確認し、エラーバジェット(許容できる障害の残り枠)がどのくらい残っているかをチェックします。
エラーバジェットが残り少なくなっている場合は、新機能リリースを一時的に抑制したり、改善に優先的に取り組んだりという判断につながります。
15:00〜17:00 コードレビュー・ドキュメント整備
Runbook(障害対応手順書)やPlaybook(運用手順書)の更新・整備を行います。SREの現場では「属人化した知識をドキュメントに落とし込む」ことが重要視されます。
17:00〜 翌日の準備・オンコール引き継ぎ
翌日以降のオンコール担当者への引き継ぎ事項をまとめ、Slackやインシデント管理ツールに記録します。アラートの誤検知が多い場合はルールを調整して帰宅する、という流れが一般的です。
SREがよく使うツール一覧
SREの現場では多数のツールが使われますが、大きく4つのカテゴリに分けると整理しやすくなります。
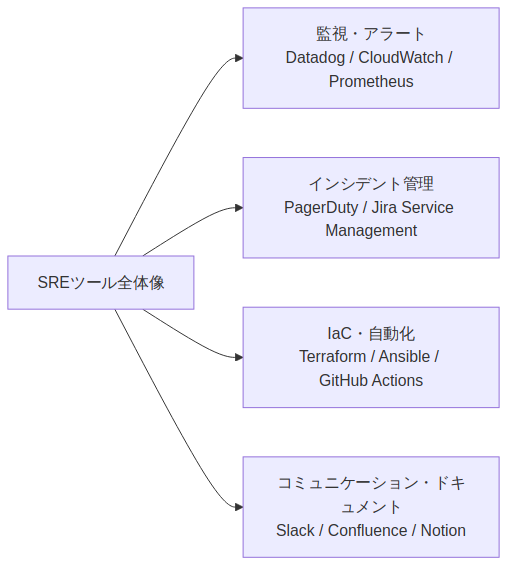
監視・オブザーバビリティ系(Prometheus / CloudWatch / OpenTelemetry)
監視ツールは、システムの状態をリアルタイムで把握するためのツールです。SREが最も日常的に触れるカテゴリといえます。
- Prometheus / CloudWatch(メトリクス収集)
- OpenTelemetry(計装の新標準。メトリクス+トレース+ログを一元化)
※ OTel導入でPrometheusをリプレースする現場も増えている - Grafana(可視化)
- PagerDuty(アラート通知)
SREの監視業務で意識すべき指標として、Googleの4つのゴールデンシグナル(レイテンシ・トラフィック・エラー・サチュレーション)があります。これらがアラート設定の基準になります。
AWSを使った監視の設計については「SRE求人票から逆算|AWSエンジニアがSRE転職に必要なスキルと優先順位」でも触れています。
インシデント管理系(PagerDuty / Jira Service Management)
監視ツールがアラートを検知したとき、「誰に・どのように通知するか」 を管理するのがインシデント管理ツールです。
| ツール | 特徴 |
|---|---|
| PagerDuty | 業界標準。オンコールローテーション管理・エスカレーション設定が充実。日本法人あり |
| Jira Service Management | Atlassian製。Jiraと統合されたインシデント管理・オンコール機能を提供 |
| Alertmanager | Prometheus用のアラート管理。OSS |
PagerDutyでは、Datadogなどの監視ツールからアラートを受け取り、担当者のスマートフォンに電話・SMSで通知します。深夜のオンコール対応でも確実に気づける仕組みを作るのがSREの重要な仕事の一つです。
IaC・自動化系(Terraform / Ansible / GitHub Actions)
SREの「Toil削減」を実現する中心的なツール群です。インフラをコードで管理し、繰り返し作業を自動化します。
| ツール | 種別 | 主な用途 |
|---|---|---|
| Terraform | IaC | AWSリソースをコードで管理・バージョン管理 |
| Ansible | 構成管理 | サーバーの設定を自動化・冪等性を担保 |
| GitHub Actions | CI/CD | テスト・デプロイ・インフラ変更を自動化 |
| AWS CDK / CloudFormation | IaC | AWSネイティブのインフラコード管理 |
TerraformはSRE転職の求人票でも最頻出のツールです。「インフラをGitで管理する」という考え方(GitOps)はSREの基本スキルとして求められます。
コミュニケーション・振り返り系(Slack / Notion / ポストモーテム)
SREはエンジニアリングだけでなく、チーム横断でのコミュニケーション も重要な業務です。
| ツール / 文化 | 用途 |
|---|---|
| Slack | インシデント発生時のリアルタイム共有・#incident チャンネルでの対応記録 |
| Notion / Confluence | Runbook・Playbook・ポストモーテムの管理 |
| ポストモーテムテンプレート | 障害発生後の振り返りをblameless(責任追及なし)で記録 |
| JIRA / Linear | SREチームのタスク・バックログ管理 |
特に ポストモーテム(障害振り返り文書) の文化はSREチームの特徴です。「誰が悪かったか」ではなく「どういうシステム的要因があったか」を分析し、再発防止策を記録します。
SREになるためにこれらのツールをどう学ぶか
まず「監視」から入るのがおすすめな理由
SREに必要なツールは多岐にわたりますが、最初に監視ツールを学ぶことをおすすめします。
理由は3つあります。
- SREの仕事の入口が監視だから: SLOを設定するにも、インシデントに対応するにも、まず「何を測るか」が起点になります。
- CloudWatchはAWSアカウントがあれば今日から触れる: 初期費用なしで学習環境を作れます。
- 求人票でも監視スキルが最も多く求められる: DatadogやCloudWatchの経験は転職市場でも評価されやすいです。
自宅環境で試せるツールと試せないツール
| ツール | 自宅学習 | 理由 |
|---|---|---|
| CloudWatch | ◎ | AWSフリーティアで試せる |
| Prometheus + Grafana | ◎ | DockerでローカルにOSS環境を構築可能 |
| Terraform | ◎ | ローカルでコードを書いてAWSに適用できる |
| Datadog | ○ | 14日間の無料トライアルあり |
| PagerDuty | ○ | 無料プランあり(機能制限付き) |
| GitHub Actions | ◎ | GitHubアカウントがあれば無料で使える |
まずは CloudWatch + Terraform + GitHub Actions の3セットを自宅のAWS環境で動かしてみるのが、SRE転職に向けた学習の第一歩として効果的です。
Udemyや公式ドキュメントで学べるリソース
体系的にSREスキルを学ぶなら、書籍・動画・公式ドキュメントを組み合わせるのが効率的です。
- 書籍: 『SRE サイトリライアビリティエンジニアリング』(Google著)— SREの原典。概念理解に最適
- Udemy: AWS×SRE入門〜CloudWatchで学ぶ監視設計の基礎〜 — CloudWatchの設定・アラート設計・SLOの考え方を体系的に学べる日本語コース
- 公式ドキュメント: AWSのCloudWatchドキュメント、TerraformのGet Startedガイド
まとめ
本記事では、SREエンジニアの1日の業務タイムラインとよく使うツールを解説しました。
この記事のポイント
- SREの仕事は「信頼性を維持・向上させるためのエンジニアリング」が中心
- 1日の流れは「アラート確認 → 朝会 → 改善タスク → SLO確認 → ドキュメント整備」が基本
- ツールは4カテゴリ(監視・インシデント管理・IaC・コミュニケーション)に分けて理解すると整理しやすい
- 学習の入口は CloudWatch + Terraform + GitHub Actions から始めるのが効率的
SREへの転職を検討しているなら、まず求人票を実際に見て、どんなツールが求められているかを確認することが大切です。
SRE・DevOpsが求人票でどう使われているかは「SRE・DevOps・インフラエンジニア、3つの違いを図解で整理する」もあわせてご覧ください。
SRE転職を考えるなら、まず求人票を見てみましょう
「SREとして転職できるレベルか知りたい」「どんなスキルが足りないか確認したい」という方は、SRE・インフラ系に強い転職エージェントに相談するのが近道です。無料で現在のスキルをもとにアドバイスをもらえます。

コメント