
「本番環境が壊れていないのに、本当に壊れた時に対応できると言えますか?」
システムの可用性を数値で語るSREにとって、これは避けられない問いです。99.9%のSLOを掲げていても、実際に障害が起きたとき想定通りに復旧できるかどうかは、訓練なしには確認できません。
その答えがカオスエンジニアリングです。意図的に障害を注入し、システムの弱点を事前に発見する実践的なアプローチです。そしてAWSが提供するAWS FIS(Fault Injection Simulator)を使えば、その障害実験を安全・再現可能な形で自動化できます。
この記事では、カオスエンジニアリングの概念から、AWS FISを使った実践的な障害訓練の手順まで解説します。
この記事でわかること
– カオスエンジニアリングの定義・原則・始め方
– AWS FIS(Fault Injection Simulator)の概要とできること
– AWS FISを使った障害実験の手順(IAMロール設定〜結果分析まで)
– 実践的なカオス実験の例(EC2停止・CPU負荷・ネットワーク遅延)
– 本番環境で適用する前に押さえるべきベストプラクティス
対象読者: SREや運用エンジニアとして、システムの信頼性向上に取り組んでいる方。SLO・インシデント対応フローは整備済みで、次のステップとして障害訓練に取り組みたい方に適しています。

カオスエンジニアリングとは
定義と背景
カオスエンジニアリング(Chaos Engineering)は、本番環境の障害に対するシステムの耐性を事前に確認するために、意図的に障害を注入する実験的手法です。
この概念を広めたのはNetflixです。2011年、NetflixはAWSへの移行後に「いつAWSが落ちても自動で復旧できる仕組み」を検証するため、Chaos Monkeyというツールを開発しました。Chaos Monkeyは本番環境のEC2インスタンスをランダムに停止させ、エンジニアがいなくてもシステムが自動復旧できるかどうかを日常的にテストし続けました。
このアプローチは、「壊れないことを祈るより、壊れても大丈夫な仕組みを作る」 というSRE哲学と完全に一致しています。
カオスエンジニアリングの5つの原則
Principlesofchaos.orgが定義するカオスエンジニアリングの原則は以下の5つです。
| 原則 | 内容 |
|---|---|
| ① 定常状態仮説を立てる | 「正常時のシステムはこう動く」という仮説を定量的に設定する |
| ② コントロールグループと実験グループを比較する | 障害を注入したグループとしないグループを比較して変化を測る |
| ③ 本番環境に近い条件で実験する | 本番と乖離した環境での実験結果は信頼できない |
| ④ 爆発範囲(Blast Radius)を最小化する | 実験の影響範囲を最小限にしてリスクをコントロールする |
| ⑤ 自動化して継続的に実行する | 一度きりの実験ではなく、定期的に繰り返す |
特に重要なのは①と④です。「何が壊れたか」を検知するにはSLOやモニタリングの整備が前提になります。また「意図しない範囲まで壊れた」事故を防ぐため、影響範囲を設計の段階でコントロールすることが不可欠です。
カオスエンジニアリングとSLOの関係
カオスエンジニアリングはSLOと一体で機能します。実験前に「この実験でSLOが何%悪化するか」を仮説として立て、実験後に実際の変化を比較します。
SLO・エラーバジェット・インシデント対応フローが未整備の状態でカオスエンジニアリングを始めるのは危険です。「何が正常か」「何が異常か」を定義できていない状態で障害を注入しても、実験なのか本物の障害なのか判断できません。
AWS FIS(Fault Injection Simulator)とは
サービス概要
AWS FIS(Fault Injection Simulator)は、AWSがマネージドサービスとして提供するカオスエンジニアリングプラットフォームです。2021年3月にGAされ、EC2・EKS・RDS・ECS・Lambda・Networkなど主要なAWSリソースへの障害注入に対応しています。
FISを使う前は、各チームが独自のスクリプトを書いて障害を再現していました。FISはその仕組みをAWSネイティブの形で標準化・安全化したものです。
AWS FISでできること
FISがサポートする主なアクションカテゴリは以下のとおりです。
| カテゴリ | アクション例 |
|---|---|
| EC2 | インスタンス停止・再起動・CPU/メモリ負荷注入 |
| EKS / Kubernetes | ノード停止・Podへのネットワーク遅延注入 |
| RDS | DBインスタンス再起動・フェイルオーバー強制 |
| ECS | タスク停止・コンテナへのCPU負荷注入 |
| Network | レイテンシ追加・パケットロス・帯域幅制限 |
| Systems Manager | カスタムドキュメント実行(任意のコマンド注入) |
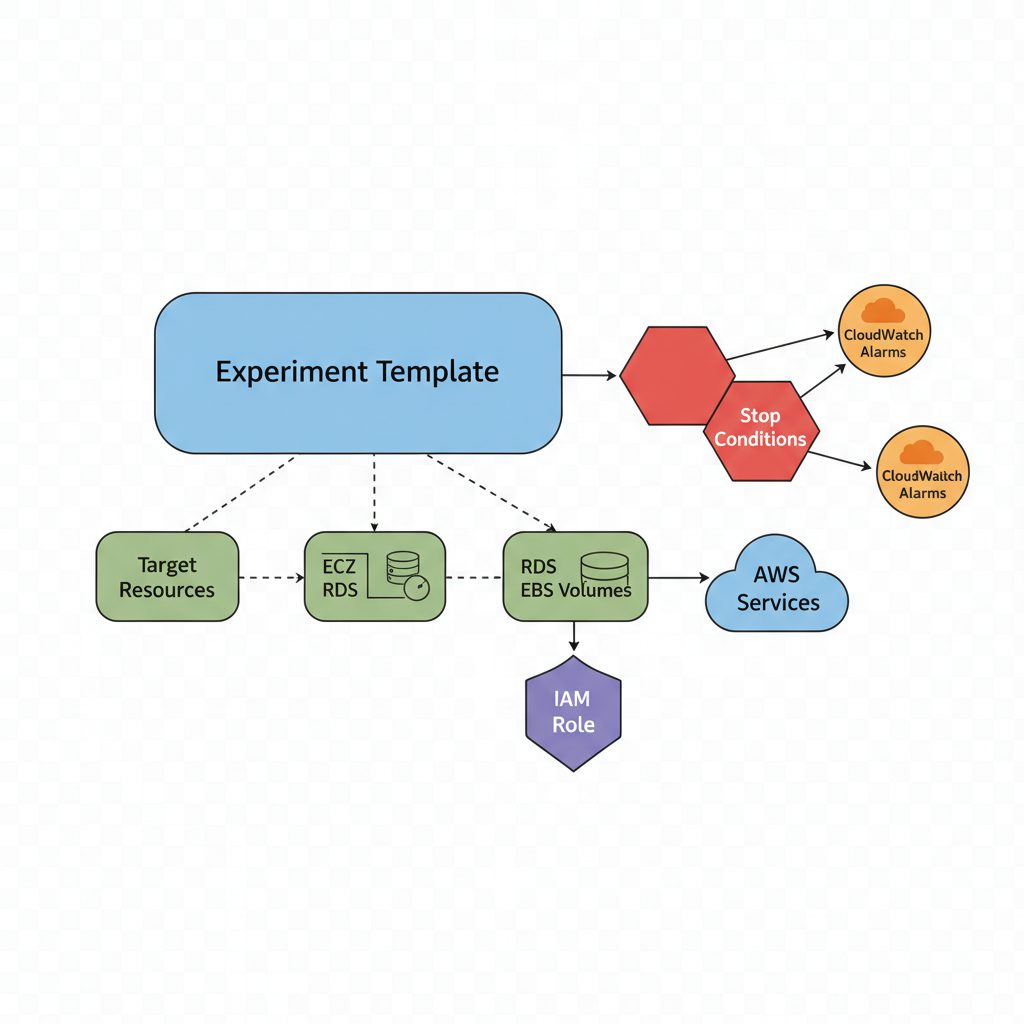
AWS FISの3つの安全機構
FISが他の手法と異なるのは、安全機構が組み込まれている点です。
① ストップ条件(Stop Conditions)
CloudWatchアラームと連携し、監視指標が閾値を超えたら実験を自動停止できます。SLOが悪化し始めたら即座に実験を止める仕組みを作れます。
② ターゲットフィルタリング
「特定のタグがついたリソースのみ」「特定のAZのみ」など、実験対象を精密に絞り込めます。本番全体に影響を与えず、影響範囲を設計できます。
③ IAMによるアクセス制御
FISの実行権限をIAMロールで管理します。誰がどの実験を実行できるかを組織のポリシーとして定義できます。
カオスエンジニアリングを始める前の準備
カオスエンジニアリングは準備なしに始めると本物のインシデントになります。以下の3点が整っていることを確認してください。
1. SLOとモニタリングの整備
実験の「定常状態」を定義できていること。最低限、以下が必要です。
- CloudWatchで主要メトリクス(CPU・レイテンシ・エラー率)が計測されている
- SLO(例:成功率99.9%・P99レイテンシ200ms以下)が定義されている
- CloudWatchアラームがFISのストップ条件として使える状態にある
2. インシデント対応フローの確立
実験が想定外に拡大したときの対応手順が明確であること。誰がどのコマンドで「止める」かが決まっていることが前提です。(インシデント対応フローの設計を参照)
3. ステージング環境での事前検証
最初の実験は本番ではなくステージング環境で実施します。実験テンプレートの設定ミスや想定外の影響範囲がないかを確認してから本番に移行します。
AWS FISで障害訓練を実施する手順
Step 1: IAMロールの準備
FISには2種類のIAMロールが必要です。
① FIS実験ロール(Experiment Role)
FISが障害注入アクションを実行するためのロール。EC2・RDS・ECSなど対象リソースへのアクセス権限を付与します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "fis.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
アタッチするポリシーの例(EC2停止・CPU負荷注入の場合):
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ec2:StopInstances",
"ec2:DescribeInstances",
"ssm:SendCommand",
"ssm:GetCommandInvocation",
"ssm:ListCommands"
],
"Resource": "*"
}
]
}
Step 2: Experiment Template(実験テンプレート)の作成
FISの実験はすべてExperiment Templateとして定義します。テンプレートには「何を」「どのリソースに」「どのような安全条件下で」実行するかを記述します。
例:CPU負荷注入テンプレート(EC2対象)
{
"description": "EC2インスタンスにCPU負荷を注入するカオス実験",
"targets": {
"WebServers": {
"resourceType": "aws:ec2:instance",
"resourceTags": {
"env": "staging",
"role": "web"
},
"selectionMode": "PERCENT(50)"
}
},
"actions": {
"InjectCPUStress": {
"actionId": "aws:ssm:send-command",
"description": "CPU使用率を80%に30分間引き上げる",
"parameters": {
"documentArn": "arn:aws:ssm:ap-northeast-1::document/AWSFIS-Run-CPU-Stress",
"documentParameters": "{\"CPU\": \"0\", \"Percent\": \"80\", \"Duration\": \"PT30M\"}",
"duration": "PT35M"
},
"targets": {
"Instances": "WebServers"
}
}
},
"stopConditions": [
{
"source": "aws:cloudwatch:alarm",
"value": "arn:aws:cloudwatch:ap-northeast-1:123456789012:alarm:SLO-SuccessRate-Critical"
}
],
"roleArn": "arn:aws:iam::123456789012:role/FISExperimentRole"
}
テンプレートの重要パラメータ解説
| パラメータ | 説明 |
|---|---|
resourceTags |
実験対象リソースのタグフィルター。env=stagingを指定すれば本番には影響しない |
selectionMode |
ALL(全台)またはPERCENT(N)(N%ランダム選択)。最初は少ない割合から始める |
stopConditions |
CloudWatchアラームのARNを指定。アラームが鳴ったら実験を自動停止 |
duration |
アクションの実行時間。実験は必ず有限時間で終わるように設定する |
Step 3: 実験の実行
AWSコンソールまたはCLIから実験を開始します。
# CLIでの実験開始
aws fis start-experiment \
--experiment-template-id EXTxxxxxxxxxxxx \
--region ap-northeast-1
# 実験ステータスの確認
aws fis get-experiment \
--id EXPxxxxxxxxxxxx \
--region ap-northeast-1
実験中にモニタリングすること
- CloudWatchダッシュボードでSLI(成功率・レイテンシ)の変化を確認
- ALBのHTTP 5xx比率
- EC2インスタンスのCPUメトリクス
- アプリケーションログのエラー数
Step 4: 結果の分析とポストモーテム
実験終了後は結果を分析し、仮説との差異を記録します。
記録すべき項目
実験名: EC2 CPU負荷注入(Staging)
実施日: 2026-04-26
対象: Webサーバー50%(2台)
実施時間: 30分
【仮説】
- CPU 80%でもALBのヘルスチェックが通り、残り2台でリクエストを処理できる
- 成功率は99.0%以上を維持できる
【結果】
- 成功率: 99.6%(仮説通り ✅)
- P99レイテンシ: 320ms → 580ms(仮説より劣化 ⚠️)
- Auto Scalingが遅延なく動作したことを確認 ✅
【発見された問題】
- レイテンシ増加が想定より大きかった。原因: セッションスティッキーにより
負荷が偏っていた可能性あり。調査が必要。
【次のアクション】
- セッション管理の見直しを検討
- レイテンシのSLOを見直す(現在P99 400msが適切かを再評価)
この記録はポストモーテムと同じフォーマットで残すと、チームの知識資産になります。(ポストモーテムの書き方を参照)
実践的なカオス実験パターン
パターン① RDSフェイルオーバー実験
マルチAZ構成のRDSが自動フェイルオーバーし、アプリケーションが接続を回復できるかを確認します。
{
"actions": {
"RDSFailover": {
"actionId": "aws:rds:failover-db-cluster",
"targets": {
"Clusters": "MyRDSCluster"
}
}
},
"targets": {
"MyRDSCluster": {
"resourceType": "aws:rds:cluster",
"resourceArns": [
"arn:aws:rds:ap-northeast-1:123456789012:cluster:my-aurora-cluster"
]
}
}
}
確認ポイント: フェイルオーバー完了まで何秒かかるか。その間のアプリケーションエラー数は許容範囲内か。
パターン② ネットワーク遅延注入
EKSノードのPodに対してネットワーク遅延を注入し、タイムアウト設定の妥当性を確認します。
{
"actions": {
"NetworkLatency": {
"actionId": "aws:network:latency",
"parameters": {
"delayMilliseconds": "200",
"jitterMilliseconds": "50",
"duration": "PT15M"
},
"targets": {
"Instances": "EKSNodes"
}
}
}
}
確認ポイント: 200ms遅延でサービス間通信のタイムアウトが発生しないか。リトライロジックが正しく機能するか。
パターン③ EC2インスタンス停止
複数台構成のWebサーバーのうち1台を停止し、ロードバランサーが自動的にトラフィックを振り分けることを確認します。
{
"actions": {
"StopInstance": {
"actionId": "aws:ec2:stop-instances",
"targets": {
"Instances": "WebServers"
}
}
},
"targets": {
"WebServers": {
"resourceType": "aws:ec2:instance",
"resourceTags": {"role": "web", "env": "staging"},
"selectionMode": "COUNT(1)"
}
}
}
カオスエンジニアリングのベストプラクティス
① 小さく始める
最初の実験は影響が最小のもの(ステージング環境・非本番時間帯・影響範囲が限定的なコンポーネント)から始めます。「いきなり本番のDBフェイルオーバー」は危険です。
難易度の目安:
初級: ステージング環境でのEC2停止(1台)
中級: 本番環境の一部インスタンスへのCPU負荷注入
上級: 本番環境でのAZフェイルオーバー・RDSフェイルオーバー
② ストップ条件を必ず設定する
FISの実験を開始する前に、CloudWatchアラームをストップ条件として設定してください。「SLOが99.0%を下回ったら自動停止」のようなアラームを必ず用意します。これがないと、実験が手を離れて本物のインシデントになります。
③ GameDay を活用する
定期的に「障害対応訓練の日(GameDay)」を設け、チーム全員でカオス実験と対応訓練を行います。実際に対応手順を実行することで、Runbookの問題・手順の抜けに気づけます。
オンコール対応チーム全員が参加し、「本当に対応できるか」を確認する場として活用します。
④ 実験結果を継続的に管理する
カオスエンジニアリングは一度やって終わりではありません。Experiment Templateをバージョン管理し、定期的に実行する仕組みにします。CI/CDパイプラインに組み込んで「リリースのたびに自動実験」する運用が理想です。
よくある失敗と注意点
ストップ条件なしで実験を開始する
最も多い失敗です。「監視していれば大丈夫」という油断は禁物です。ストップ条件を設定せずに実験を始めると、想定外の影響が広がっても手動で止めるまで継続してしまいます。
本番環境から始める
理論上は問題なくても、Experiment Templateの設定ミスが本番環境に影響する可能性があります。必ずステージングで検証してから本番に適用します。
仮説を立てずに実験する
「壊してみよう」という好奇心だけで実験しても、得られるものが少ないです。「この実験で何を確認したいのか」という仮説を事前に設定し、それに対する検証として実験を位置づけます。
チームの合意なしに実施する
カオスエンジニアリングは意図的に障害を起こす行為です。チーム・関係者への事前告知と合意なしに実施すると、インシデントとして扱われる可能性があります。「これは実験です」という共通認識を持った上で実施します。
まとめ
カオスエンジニアリングのポイントを整理します。
- カオスエンジニアリングは「壊れても大丈夫か」を事前に確認する実践的な手法
- AWS FISを使えば、安全機構(ストップ条件・ターゲットフィルタリング)付きで障害実験を自動化できる
- 始める前にSLO・モニタリング・インシデント対応フローの整備が必須
- 小さく始めてステージング→本番と段階的に適用する
- 実験後はポストモーテム形式で記録し、チームの知識資産として残す
カオスエンジニアリングはSLOやポストモーテムと並ぶ、SRE実務の核心的なプラクティスです。「障害が起きたらどうしよう」という不安を「障害が起きても大丈夫」という確信に変える、最も実践的な方法です。
SRE実務をAWSで体系的に学びたい方へ
本記事で解説したカオスエンジニアリングを含め、SLO設計・インシデント対応・オブザーバビリティなどSREの実務スキルを体系的に学べるUdemyコースを公開しています。
CloudWatchによる監視設計からSLO管理まで、AWS環境でのSRE実践をハンズオンで習得できる内容です。


コメント