
本記事では、SRE・インフラエンジニアが必ず押さえるべき オブザーバビリティの3本柱(メトリクス・ログ・トレース) の概念と、AWSでの実装方法を解説します。
この記事でわかること
- オブザーバビリティとモニタリングの違い
- メトリクス・ログ・トレースそれぞれの役割と特性
- 3本柱の使い分けと組み合わせパターン
- AWSでオブザーバビリティを実装する構成(CloudWatch・X-Ray・OpenTelemetry)
前提条件
- AWSの基礎知識(EC2・Lambda・ECSなどの操作経験)
- システム監視の基本的な概念を理解していること

オブザーバビリティとモニタリングの違い
まず、オブザーバビリティ(Observability) と モニタリング(Monitoring) の違いを整理します。この2つは混同されやすいですが、設計思想がまったく異なります。
モニタリングとは
モニタリングは「事前に想定した異常を検知する」アプローチです。CPU使用率が90%を超えたらアラート、エラーレートが1%を超えたらアラート——このように、あらかじめ定義したしきい値を監視します。
既知の問題には強いですが、「想定外の障害」には対応できないのが限界です。
オブザーバビリティとは
オブザーバビリティは「システムの内部状態を外部から観察できる状態にする」という設計哲学です。制御工学の概念を転用したもので、「何が起きたか」だけでなく「なぜ起きたか」「どこで起きたか」を解明できる状態を目指します。
| 観点 | モニタリング | オブザーバビリティ |
|---|---|---|
| 目的 | 既知の問題を検知する | 未知の問題を調査・解明する |
| アプローチ | しきい値を監視する | システムの状態を可視化する |
| 強み | アラートの自動化 | 原因の深掘り・根本分析 |
| 限界 | 想定外の障害に弱い | データ量・コストが増える |
現代のSRE運用では、モニタリングとオブザーバビリティを 組み合わせて使う のが標準です。モニタリングで「異常を検知」し、オブザーバビリティで「原因を特定」します。

オブザーバビリティの3本柱
オブザーバビリティを構成する3つのデータ種別が メトリクス・ログ・トレース です。それぞれが異なる観点からシステムを観測し、組み合わせることで全体像を把握できます。
graph TD A["オブザーバビリティ"] B["① メトリクス 何が起きているか"] C["② ログ なぜ起きているか"] D["③ トレース どこで起きているか"] A --> B A --> C A --> D B --> E["CloudWatch Metrics"] C --> F["CloudWatch Logs"] D --> G["AWS X-Ray"]
3本柱①メトリクス
メトリクスとは
メトリクスは、時系列で集計された数値データ です。「今この瞬間、システムがどのような状態にあるか」を定量的に把握します。
- CPU使用率: 78%
- リクエスト数: 1,200 req/sec
- エラーレート: 0.3%
- レスポンスタイム(P99): 450ms
特徴は 軽量・高速・安価 であることです。1秒ごとに収集しても保存コストは低く、長期トレンドの把握に適しています。
メトリクスが答える問い
「今、何が起きているか?」
- CPUが高騰している → インスタンスのスペックが足りていない可能性
- エラーレートが急増 → 何らかの障害が発生している
- レイテンシが上昇 → データベースかネットワークがボトルネック
メトリクスの限界
数値の変化は検知できますが、「なぜその数値になったか」はわかりません。CPU使用率が90%になった原因がプログラムのバグなのか、急なトラフィック増加なのか、メトリクス単体では判断できません。
AWSでのメトリクス実装
AWSでは Amazon CloudWatch Metrics がメトリクス収集の中核です。EC2・Lambda・RDS・ALBなどのマネージドサービスのメトリクスは自動収集されます。
カスタムメトリクスは AWS SDK または CloudWatch エージェントで送信します。
# AWS CLIでカスタムメトリクスを送信する例
aws cloudwatch put-metric-data \
--namespace "MyApp/Performance" \
--metric-name "ResponseTime" \
--value 125 \
--unit Milliseconds
CloudWatch の詳細な設定方法については「Amazon CloudWatchとは?SREが押さえるべき監視の基本」を参照してください。
3本柱②ログ
ログとは
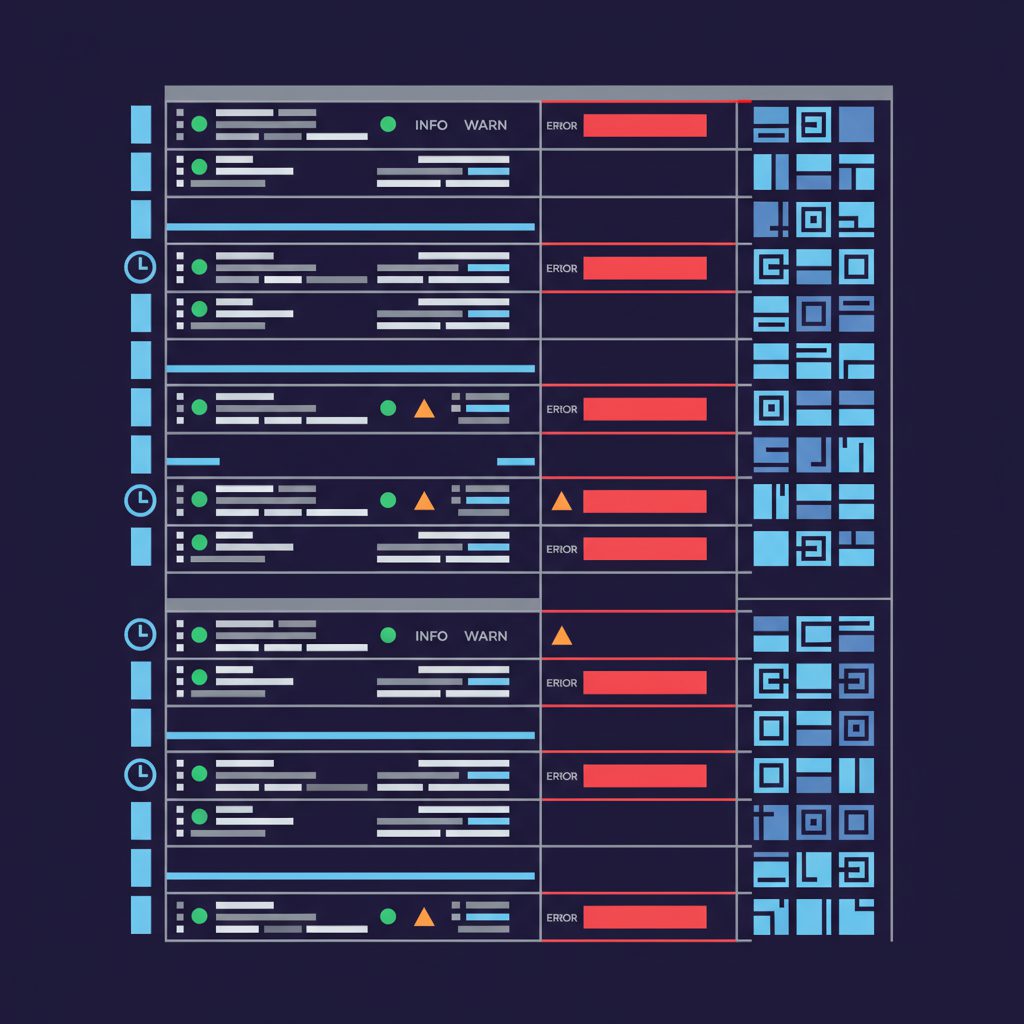
ログは、アプリケーションやシステムが出力するテキスト形式のイベント記録 です。「ある時点で何が起きたか」を詳細に記録します。
{
"timestamp": "2026-04-22T10:15:30Z",
"level": "ERROR",
"message": "Database connection timeout",
"service": "order-service",
"userId": "user-12345",
"duration_ms": 5023,
"error_code": "DB_TIMEOUT"
}
ログが答える問い
「なぜ、それが起きたか?」
- エラーメッセージの詳細 → 例外の種類・スタックトレース
- ユーザーの操作履歴 → 「どのユーザーが何をしたときに問題が起きたか」
- 外部APIのレスポンス → 「依存サービスが何を返したか」
メトリクスで「エラーレートが1%上昇した」と検知したあと、ログで「なぜそのエラーが起きたか」を掘り下げるのが実務の標準フローです。
構造化ログの重要性
ログの価値を最大化するには 構造化ログ(Structured Logging) が不可欠です。プレーンテキストではなく、JSON形式で出力することで、後からのフィルタリング・集計が容易になります。
| 形式 | 例 | 検索性 |
|---|---|---|
| 非構造化(テキスト) | ERROR 2026-04-22 DB timeout for user-12345 |
低い(grep頼み) |
| 構造化(JSON) | {"level":"ERROR","error":"DB timeout","userId":"user-12345"} |
高い(クエリで集計可能) |
AWSでのログ実装
AWSでは Amazon CloudWatch Logs がログ収集・管理の中核です。CloudWatch Logs Insights を使うと、SQLライクなクエリでログを分析できます。
-- エラーログを集計するCloudWatch Logs Insightsクエリ
fields @timestamp, @message, level
| filter level = "ERROR"
| stats count() as errorCount by bin(5m)
| sort @timestamp desc
CloudWatch Logsの詳細は「CloudWatch Logsの使い方完全ガイド|SREが実務で使うログ監視・Insights分析」を参照してください。
3本柱③トレース(分散トレーシング)
トレースとは
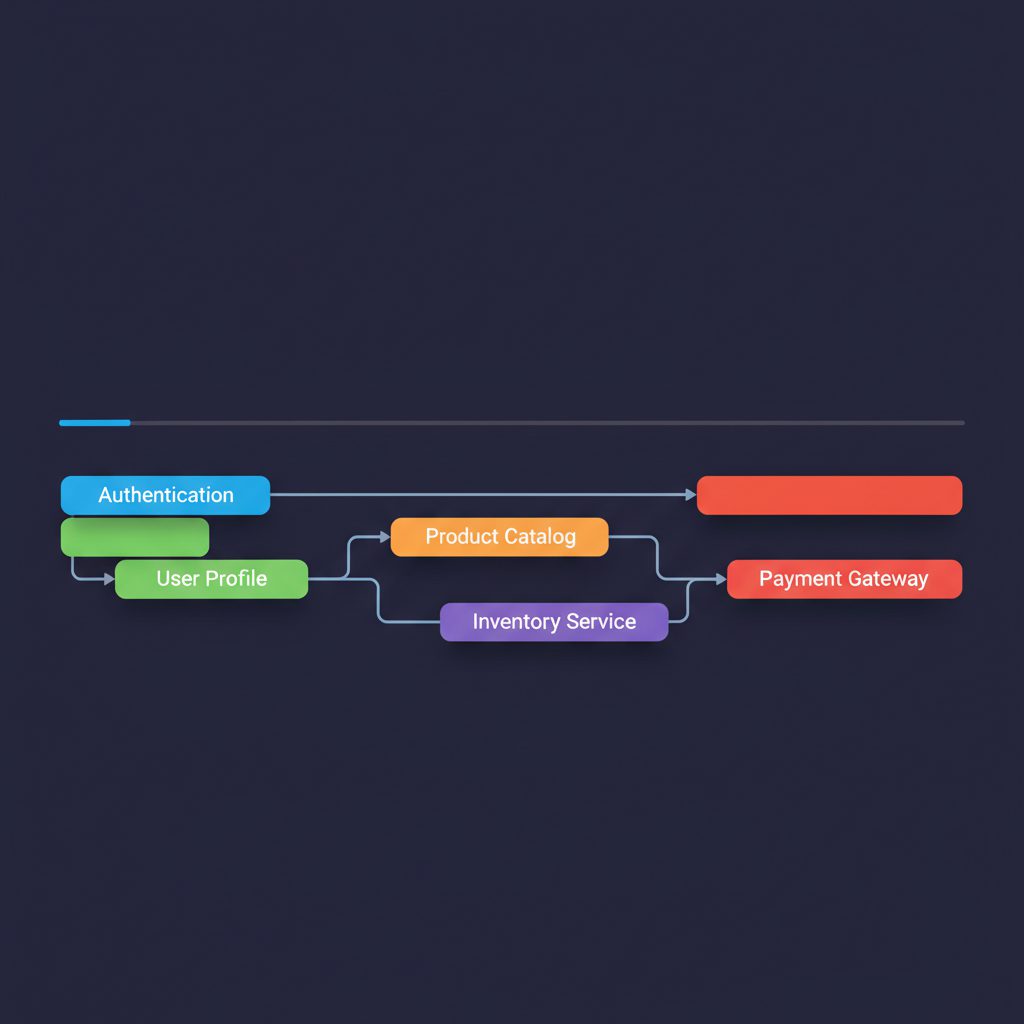
トレースは、1つのリクエストがシステムを通過する経路と処理時間を記録したデータ です。マイクロサービスやサーバーレス構成のように、複数のサービスをリクエストが横断する環境で威力を発揮します。
graph TD A["クライアント"] B["API Gateway 12ms"] C["認証サービス 35ms"] D["注文サービス 180ms"] E["在庫サービス 25ms"] F["データベース 150ms ⚠️ボトルネック"] A --> B --> C --> D --> E --> F
トレースがあれば、「合計レスポンスタイム 402ms のうち、データベース処理に 150ms かかっている」というボトルネックを一目で特定できます。
トレースが答える問い
「どこで、それが起きたか?」
- どのサービスで処理時間がかかっているか
- どのサービスでエラーが発生しているか
- サービス間の依存関係と呼び出し順序
トレースの構成要素
| 用語 | 意味 |
|---|---|
| トレース | 1リクエストの処理全体の記録 |
| スパン | 各サービス・処理の単位(開始〜終了時刻) |
| トレースID | 複数サービスをまたぐリクエストを紐付けるID |
| 親子関係 | サービス間の呼び出し階層 |
AWSでのトレース実装
AWSでは AWS X-Ray が分散トレーシングのマネージドサービスです。Lambda・ECS・EC2・API Gatewayなど主要サービスに対応しています。
# AWS X-Ray SDKを使ったPythonコードの例(Lambda)
from aws_xray_sdk.core import xray_recorder
@xray_recorder.capture('process_order')
def process_order(order_id):
# この関数の処理がX-Rayのサブセグメントとして記録される
return fetch_from_db(order_id)
AWS X-Rayの詳細な設定は「AWS X-Rayとは?分散トレーシングの仕組みと設定手順【入門ガイド】」を参照してください。
3本柱の使い分けと組み合わせパターン
いつ何を使うか
| シナリオ | 使うべきデータ | 理由 |
|---|---|---|
| 「今サービスは正常か?」 | メトリクス | 数値でリアルタイム状態確認 |
| 「アラートが出た。何が起きた?」 | メトリクス + ログ | 数値→詳細へ掘り下げ |
| 「レスポンスが遅い。どこが原因?」 | トレース | サービス間のボトルネック特定 |
| 「ユーザーからエラー報告。何が起きた?」 | ログ + トレース | 当該リクエストの詳細追跡 |
| 「昨日の23時から何かおかしい」 | メトリクス + ログ | 時系列の傾向分析 |
障害対応での実践的な使い方
実務でのインシデント対応では、以下の順序で3本柱を使います。
graph TD A["🚨 アラート発生"] B["メトリクス確認 どの指標が異常か?"] C["ログ調査 なぜ異常が起きているか?"] D["トレース確認 どのサービスが原因か?"] E["原因特定・対処"] A --> B --> C --> D --> E
- メトリクスでアラートの概要を把握(「エラーレートが5倍になっている」)
- ログでエラーの詳細を確認(「DBへの接続タイムアウトが多発している」)
- トレースでどのサービスが起点か特定(「注文サービス→在庫サービス間のレイテンシが異常」)
AWSでオブザーバビリティを実装する構成
基本構成(CloudWatch中心)
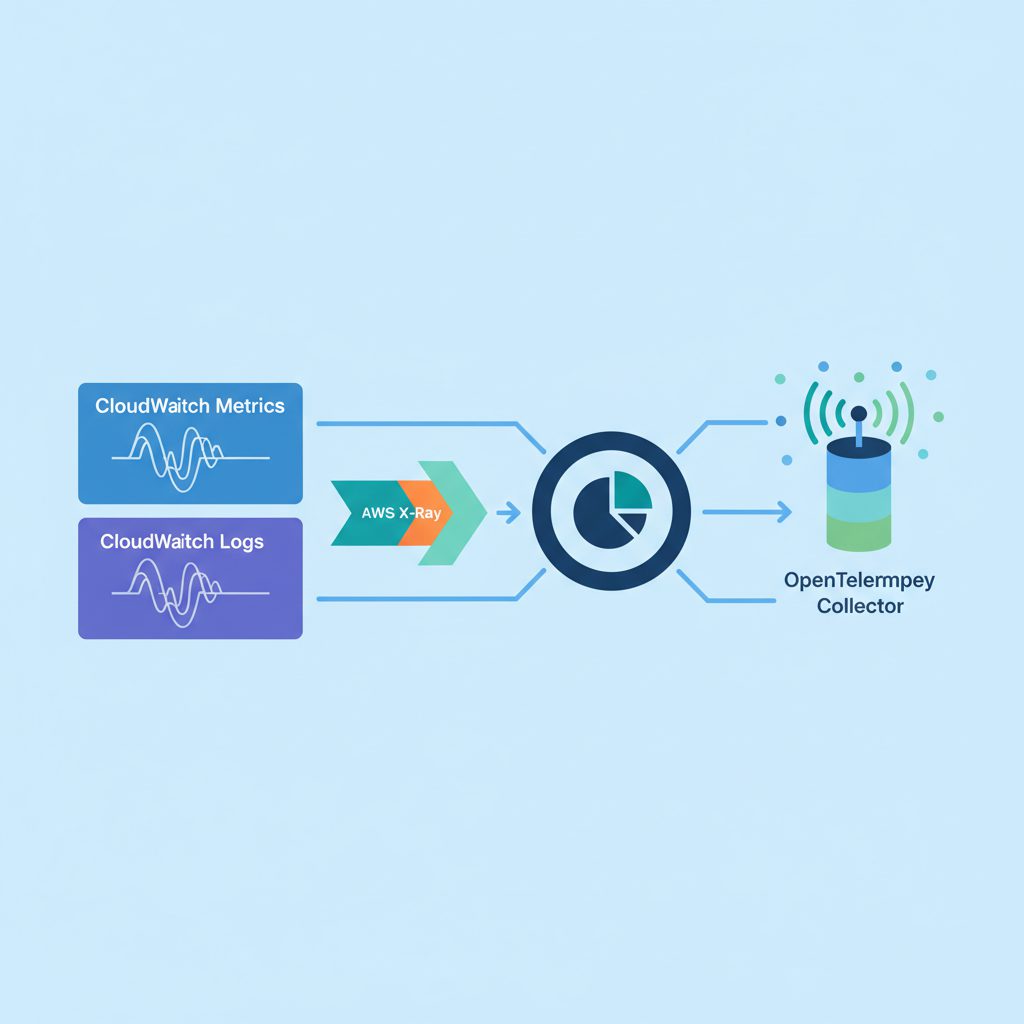
AWSのマネージドサービスを使う場合、CloudWatchが3本柱すべての起点になります。
| 柱 | AWSサービス | 役割 |
|---|---|---|
| メトリクス | Amazon CloudWatch Metrics | メトリクス収集・アラート |
| ログ | Amazon CloudWatch Logs | ログ収集・Insights分析 |
| トレース | AWS X-Ray | 分散トレーシング |
OpenTelemetryを使った標準化
ベンダーロックインを避けたい場合は OpenTelemetry(OTel) を採用します。OTelはCNCF(Cloud Native Computing Foundation)が主導するオープンスタンダードで、メトリクス・ログ・トレースの収集APIを統一します。
AWSでは AWS Distro for OpenTelemetry(ADOT) が提供されており、OTelのデータをCloudWatchやX-Rayに送信できます。
# OpenTelemetry Collector設定例(抜粋)
exporters:
awsxray:
region: ap-northeast-1
awscloudwatchmetrics:
namespace: MyApp
region: ap-northeast-1
service:
pipelines:
traces:
exporters: [awsxray]
metrics:
exporters: [awscloudwatchmetrics]
OpenTelemetryとADOTの詳細は「OpenTelemetryとAWS Distro for OpenTelemetry(ADOT)でCloudWatchに統合する」を参照してください。
コスト最適化のポイント
オブザーバビリティの課題はコストです。3本柱をすべて高頻度で収集すると、データ量が膨大になります。
| データ種別 | コスト特性 | 最適化のポイント |
|---|---|---|
| メトリクス | 比較的安価 | カスタムメトリクスの粒度を絞る |
| ログ | 量に比例して高騰しやすい | ログレベルを本番はWARN以上に絞る |
| トレース | サンプリング設定が重要 | 全トレースではなく一部をサンプリング |
X-Rayのサンプリングルールは、本番環境では「1秒あたり1件 + 5%サンプリング」が実務上のバランスが良い設定です。
まとめ
本記事では、オブザーバビリティの3本柱(メトリクス・ログ・トレース)について解説しました。
この記事のポイント
- オブザーバビリティ は「想定外の問題を解明できる状態」を目指す設計哲学
- メトリクス → 「何が起きているか」を数値で把握。軽量・安価でリアルタイム監視に最適
- ログ → 「なぜ起きているか」を詳細に記録。構造化ログで検索性を高める
- トレース → 「どこで起きているか」をリクエスト単位で追跡。マイクロサービスのボトルネック特定に必須
- 障害対応では メトリクス→ログ→トレース の順で掘り下げるのが実務標準
3本柱を正しく設計することで、障害対応の時間を大幅に短縮できます。「ログを見ているのに原因がわからない」という状況は、観測設計の問題である場合がほとんどです。
SREのスキルをより体系的に学びたい方へ
本記事で解説したオブザーバビリティの設計・実装を、実際のAWS環境で手を動かしながら学べるUdemyコースを公開しています。CloudWatch・X-Ray・OpenTelemetryの設定からSLO設計まで、SRE実務に直結する内容を網羅しています。

コメント