
障害が起きるたびに「誰が悪かったのか」を探す振り返りになっていませんか。
同じような障害が何度も繰り返される。振り返り会議が「責任の押し付け合い」になってエンジニアが発言しなくなる。形式的にドキュメントは書くが、アクションアイテムが誰も実行しないまま忘れられる——これらはすべて、ポストモーテムが正しく機能していないサインです。
SREにおけるポストモーテムは、障害の「犯人を見つける場」ではありません。システムとプロセスの弱点を学習し、同じ障害を繰り返さない組織能力を高めるための仕組みです。
この記事では、ポストモーテムの正しい書き方とblameless文化の実践方法を解説します。
この記事でわかること
– ポストモーテムとは何か(定義・目的・振り返りとの違い)
– blameless文化の本質と、犯人探しをやめる理由
– 実際に使えるポストモーテムテンプレート(必須セクション付き)
– 根本原因分析(RCA)の進め方(5Whysの使い方)
– ポストモーテムミーティングのファシリテーション方法
– よくある失敗パターンとその対策
前提条件: インシデント対応フローの基礎知識(インシデント対応フローの設計はこちら)があると理解しやすい内容です。
ポストモーテムとは
ポストモーテム(Postmortem)とは、本番環境で発生したインシデントや障害が収束したあとに実施する、体系的な振り返りプロセスです。
医療用語「post-mortem(死後検死)」に由来し、「何が起きたか・なぜ起きたか」を徹底的に解剖するという意味でこの名称が使われています。Google SREブックで定義・広められ、現在では多くのテクノロジー企業でSREプラクティスの中核に位置づけられています。
振り返りとポストモーテムの違い
一般的な「振り返り」との違いを明確にしておきます。
| 項目 | 一般的な振り返り | SREのポストモーテム |
|---|---|---|
| 目的 | 改善点の共有 | システム・プロセスの弱点を特定して再発を防ぐ |
| 焦点 | 担当者の行動 | システム・プロセスの構造的な問題 |
| 文化 | 属人的(誰が悪いか) | blameless(誰でもなく何が悪いか) |
| 出力 | 「次回は気をつけよう」 | 具体的なアクションアイテム(担当・期限付き) |
| 記録 | 議事録 | 検索・参照可能なドキュメント |
ポストモーテムの3つの目的
- 再発防止: 同じ障害を繰り返さないための根本的な改善策を特定する
- 組織学習: インシデントから得た知識をチーム全体で共有し、次の障害への対応力を高める
- 信頼性の継続的改善: システム・プロセスの弱点を可視化し、長期的なSLO達成率を向上させる
Googleでは、一定以上の深刻度(SEV1・SEV2相当)のインシデントには必ずポストモーテムの実施を義務化しています。これは「責任を取らせる」ためではなく、「学習の機会を逃さない」ためです。

blameless文化とは
blameless(ブレームレス)とは、「誰かを責めない」という文化・原則のことです。ポストモーテムの文脈では、「個人の失敗を責めるのではなく、システムとプロセスの問題として捉える」というアプローチを指します。
「犯人探し」が起きるとどうなるか
ポストモーテムで犯人を探す文化がある組織では、以下のことが起きます。
- エンジニアが障害の詳細を隠すようになる(責められたくないため)
- インシデントの真の根本原因が明らかにならず、対策が表面的になる
- オンコール担当者が障害対応を恐れるようになり、心理的安全性が損なわれる
- ミスをした人が次回の対応を避けようとするため、経験が蓄積されない
結果として、同じ障害が何度も繰り返され、チームの信頼性が上がりません。
blamelessの本質
blamelessの本質は「誰も悪くない」ということではありません。「複雑なシステムで働く優秀なエンジニアが、その状況で最善の判断をした結果として障害が起きた」という前提に立つことです。
人間はミスをします。ベテランのエンジニアでも、疲れているとき・情報が不足しているとき・時間的プレッシャーがあるときには誤った判断をします。それは「その人が悪い」のではなく、そのような判断が起きやすいシステム・プロセス・環境に問題があるという視点です。
blameless文化を根付かせる3つの原則
① 「なぜ」を繰り返す(5Whys)
「デプロイのオペミスがあった」で止まらず、「なぜそのオペミスが起きる環境だったのか」「なぜそのオペミスを防ぐ仕組みがなかったのか」まで掘り下げます。
② ファクトベースで書く
ポストモーテムには主観・感想・評価を書きません。「〇〇さんが間違えた」ではなく「〇〇時〇〇分に設定変更が行われた(変更者:匿名でも可)」と事実のみを記録します。
③ アクションアイテムはシステム・プロセス改善に向ける
「〇〇さんは次回から気をつけること」というアクションは意味がありません。「デプロイ手順にdry-runステップを追加する」「変更前のレビュー体制を設ける」など、再発を防ぐ構造的な改善策を設定します。
ポストモーテムの書き方(テンプレート)
実際に使えるポストモーテムのテンプレートを紹介します。このテンプレートはGoogle SREブックの構成をベースに、現場で使いやすいよう調整しています。
必須セクション一覧
1. インシデント概要
2. インパクト(影響範囲)
3. タイムライン(時系列)
4. 根本原因(Root Cause)
5. トリガー(直接的なきっかけ)
6. 検知方法
7. 対応の経緯
8. 教訓(Lessons Learned)
9. アクションアイテム
セクション1〜3: インシデント概要・インパクト・タイムライン
インシデント概要には以下を記載します。
- 発生日時: YYYY-MM-DD HH:MM (JST)
- 復旧日時: YYYY-MM-DD HH:MM (JST)
- 影響時間: ○○分
- 深刻度(SEV): SEV1 / SEV2 / SEV3
- 対応IC(インシデントコマンダー): [担当者名]
- 一言サマリー: [何が起きたか30文字以内で]
インパクト(影響範囲)では、ユーザーへの影響を定量的に記載します。
- 影響ユーザー数: ○○万人(全ユーザーの○○%)
- エラーレート: 通常0.1% → 最大98%
- 影響機能: 決済フロー(新規購入不可)
- SLOへの影響: エラーバジェットを○○%消費
タイムラインは時系列で事実のみを記載します。評価・感情・「〜のはずだった」は不要です。
10:00 - CloudWatch アラーム CRITICAL 発火(エラーレート > 5%)
10:03 - PagerDuty 経由で担当者 A に通知
10:08 - 担当者 A が Slack チャンネルに投稿・調査開始
10:15 - データベース接続プールの枯渇を確認
10:22 - 担当者 B がエスカレーション受理・DB チームに連絡
10:45 - コネクションプールサイズを 100 → 300 に変更・適用
10:52 - エラーレート 0.5% 以下に回復
11:00 - 全アラーム GREEN 確認・復旧完了宣言
セクション4〜6: 根本原因・トリガー・検知方法
根本原因(Root Cause)は、「5 Whys」を使って掘り下げます。
Why 1: なぜエラーが発生したか
→ データベースへの接続が確立できなかった
Why 2: なぜ接続が確立できなかったか
→ コネクションプールが枯渇していた
Why 3: なぜコネクションプールが枯渇したか
→ 想定の3倍のトラフィックが発生した
Why 4: なぜ想定の3倍のトラフィックが発生したか
→ キャンペーンによるアクセス増加を想定していなかった
Why 5: なぜキャンペーンの影響を事前に把握できていなかったか
→ エンジニアとマーケティング間の事前連携フローが存在しなかった
根本原因: マーケティングキャンペーンがインフラに与える影響を事前評価するプロセスがなかった
このように掘り下げると、「コネクションプールの設定を変更した」という表面的な対処だけでなく、「キャンペーン前のキャパシティレビューフローを整備する」という構造的な改善につながります。
トリガー(直接的なきっかけ)と根本原因は区別します。
トリガー: キャンペーン開始によるトラフィック急増
根本原因: キャンペーン影響を評価するプロセスの欠如
検知方法では、どのように障害を検知したかと、より早く検知できた可能性を記録します。
実際の検知: CloudWatch アラーム(エラーレート > 5%)が 10:00 に発火
改善余地: 接続プール使用率が 80% を超えた時点でアラートを出せれば、
エラー発生前に予防対処できた可能性がある
セクション7〜9: 教訓・アクションアイテム
教訓(Lessons Learned)は、ポストモーテムの中で最も価値があるセクションです。「うまくいったこと・うまくいかなかったこと・運が良かったこと」の3軸で記載します。
✅ うまくいったこと
- CloudWatch アラームが障害発生後 3 分以内に検知・通知できた
- オンコール担当者が 5 分以内にインシデントを認知した
- DB チームへのエスカレーションがスムーズに機能した
❌ うまくいかなかったこと
- 初動のトリアージに 7 分かかった(目標: 5 分以内)
- ランブック(Runbook)が最新化されておらず、手順確認で時間がかかった
- マーケ起因の負荷増加を事前に把握できていなかった
⚠️ 運が良かったこと
- 担当者 A が深夜ではなく平日昼間にオンコールしていた
- DB のリードレプリカが生きており、参照系への影響を最小化できた
アクションアイテムは、担当者・期限・優先度を必ずセットで設定します。
| アクション | 担当 | 期限 | 優先度 |
|---|---|---|---|
| 接続プール使用率 80% アラームを追加 | インフラチーム | 2026-05-01 | 高 |
| DB Runbook を最新化 | 担当者 A | 2026-04-30 | 高 |
| キャンペーン前キャパシティレビューフローを整備 | SRE + マーケ | 2026-05-15 | 中 |
| 負荷テスト環境を整備し、キャンペーン前に実施できるようにする | インフラチーム | 2026-06-01 | 中 |
ポストモーテムミーティングの進め方
ポストモーテムはドキュメントを書くだけでなく、チームでレビューするミーティングを実施することで効果が高まります。
ミーティングの準備
- 開催タイミング: インシデント収束後 72 時間以内(記憶が鮮明なうち)
- 参加者: IC(インシデントコマンダー)・対応メンバー・関係チームの代表者(5〜8人が理想)
- 事前配布: ミーティング 24 時間前にドラフトを参加者に共有し、コメントを受け付ける
- ファシリテーター: IC が兼務せず、別のメンバーが担当するのが理想(IC は説明側に集中)
ファシリテーションのコツ
「なぜそう判断したか」を聞く
「なぜその設定変更をしたのか」という問いは責める意図なく使えます。「その時点でどんな情報があって、どう判断したか」を引き出すことが目的です。
「他に情報があれば判断は変わったか」を掘り下げる
根本原因が「情報の欠如」に至ることは多いです。「あの時点でログが見えていれば」「アラートの閾値が違えば」という仮定から、改善アクションが生まれます。
犯人探しになったら止める
「〇〇さんがこうすれば良かった」という議論になったとき、ファシリテーターは「それを〇〇さんができる環境をどう作るか」にリダイレクトします。
graph TD
A["インシデント収束"] --> B["ドラフト作成
(IC 担当)"]
B --> C["24時間前に参加者に配布"]
C --> D["ポストモーテムミーティング
(72時間以内)"]
D --> E["アクションアイテム確定"]
E --> F["Jira / GitHub Issues に登録"]
F --> G["週次でフォローアップ"]
G --> H["全アクション完了 → クローズ"]
フォローアップとアクション管理
ミーティング後のフォローアップが最も重要であり、最も失敗しやすいフェーズです。
- アクションアイテムをすべて Jira・GitHub Issues などのタスク管理ツールに登録する
- 週次の定例ミーティングでオープンなアクションを確認する
- 期限を過ぎたアクションは原因を確認し、期限延長か優先度変更を明示的に決定する
- 全アクション完了後にポストモーテムを「クローズ」し、ステータスを更新する
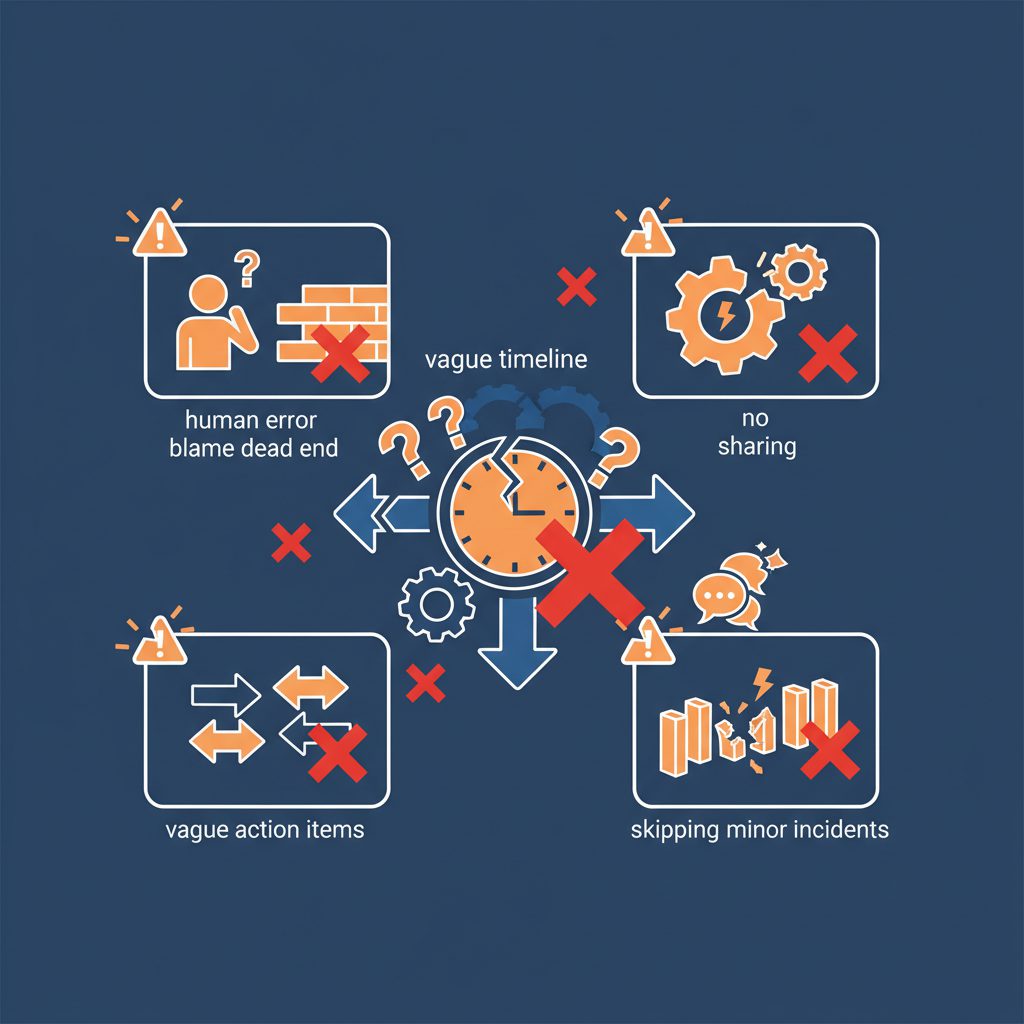
よくある失敗パターンと対策
失敗1: タイムラインが不正確・粗い
「だいたい○時ごろ」「しばらくして」という記述はポストモーテムの価値を大きく下げます。
対策: インシデント対応中からリアルタイムでログを取る習慣をつける。Slack のスレッドに時系列で投稿するだけでも、後から正確なタイムラインを作りやすくなります。
失敗2: 根本原因が「人的ミス」で止まる
「担当者が確認を怠った」「オペミスがあった」は根本原因ではなく、現象の記述に過ぎません。
対策: 「なぜそのミスが起きる環境があったのか」「なぜそのミスを防ぐ仕組みがなかったのか」と5Whysを続けます。根本原因は必ずシステム・プロセスの問題に辿り着くはずです。
失敗3: アクションアイテムが「要検討」で終わる
「○○について検討する」「○○を改善する」は行動ではありません。
対策: アクションは「何を(What)・誰が(Who)・いつまでに(When)・完了の定義(Done Criteria)」を必ず含む形で書きます。
❌ NG: 「アラート設定を見直す」
✅ OK: 「接続プール使用率 80% 超えで WARN アラームを追加する
担当: ○○ / 期限: 2026-05-01 / Done: CloudWatch で確認できる状態」
失敗4: ポストモーテムが書きっぱなしで共有されない
ポストモーテムを書いても、そのドキュメントが誰にも読まれなければ組織学習は起きません。
対策: ポストモーテムが完成したら社内の技術共有チャンネルに投稿し、類似のシステムを持つチームに通知します。定期的にポストモーテムを振り返る「ポストモーテムレビュー会」を設けると、横断的な学習が促進されます。
失敗5: 軽微なインシデントをスキップする
「大した障害じゃないから書かなくていい」という判断が続くと、同じ小さな障害が積み重なって大きな障害につながります。
対策: SEV3・SEV4 レベルでも、ニアミス(ヒヤリハット)や繰り返し発生しているものはポストモーテムを書く基準を設けます。短くても良い——1ページのポストモーテムを書く文化の方が、詳細な報告書を年1回書く文化より価値があります。
ポストモーテムとSLO運用の連携
ポストモーテムはSLO(サービスレベル目標)と連携させることで、改善の優先順位が明確になります。
例)月間 SLO: 99.9%(エラーバジェット: 43.8 分)
今月のインシデント:
- インシデント A: 25 分(バジェット消費 57%)→ ポストモーテム完了・アクション実施中
- インシデント B: 8 分(バジェット消費 18%)→ ポストモーテム完了・クローズ済み
- インシデント C: 5 分(バジェット消費 11%)→ ポストモーテム完了
残バジェット: 5.8 分(14%)
→ エラーバジェット枯渇リスク HIGH → 機能開発を一時停止し信頼性改善に集中
エラーバジェットが残り 20% を切ったら、ポストモーテムのアクションアイテムを最優先タスクとして扱う——このルールを設けることで、「ポストモーテムは書いたけど改善はいつか」という状態を防げます。
まとめ
ポストモーテムの書き方のポイントをまとめます。
- blameless: 個人を責めず、システム・プロセスの問題として捉える。犯人探しは組織学習の最大の敵
- タイムライン: 事実のみを時系列で記録する。感情・評価・推測は不要
- 5 Whys: 「人的ミス」で止まらず、「なぜそのミスが起きる環境だったのか」まで掘り下げる
- アクションアイテム: 「何を・誰が・いつまでに・完了の定義」を必ずセットで設定する
- フォローアップ: タスク管理ツールに登録し、週次でオープン状態を確認する
ポストモーテムが正しく機能している組織は、障害が起きるたびに強くなります。最初は書くことに慣れていなくても、1ページのシンプルなポストモーテムから始めて継続することが重要です。
SREにおけるインシデント対応・ポストモーテム・SLO運用を体系的に学びたい方は、Udemyコース「AWS×SRE入門〜CloudWatchで学ぶ監視設計の基礎〜」で実践的に学べます。ポストモーテムの実施演習も含まれており、手順書として活用できます。
関連記事
– インシデント対応フローの設計|検知から復旧・振り返りまでSRE流に解説
– SLI・SLOの設計方法 – CloudWatchでエラーバジェットを管理する
– CloudWatch Alarmsの設定ガイド – アラート疲れを防ぐ実践手順


コメント