本番環境で障害が起きたとき、「誰が何をすべきか」が曖昧なまま動いていませんか。
アラートが飛んでくる。Slackが騒ぎ始める。でも初動で5分・10分と時間を無駄にし、気づいたら「誰かが対応してると思ってた」という状況——これはフローが設計されていないチームで頻繁に起きます。
インシデント対応は、才能や経験に依存すべきではありません。再現性のあるフローとして設計することで、誰がオンコールに入っていても同じ品質で対応できる状態を目指します。
この記事では、SREの視点からインシデント対応フローの設計方法を解説します。
この記事でわかること
– インシデント対応フローの全体像(5つのフェーズ)
– 各フェーズで行うことと担当者の役割分担
– AWSを使ったアラート検知〜通知の仕組み
– トリアージ・エスカレーション基準の決め方
– 振り返り(ポストモーテム)の進め方
– よくある失敗パターンとその対策
前提条件: AWS基礎知識(CloudWatch・SNS)があると理解しやすい内容です。SLO・SLAの概念を把握していると、セクション3がより理解しやすくなります。

インシデント対応フローとは
インシデント対応フロー(Incident Response Flow)とは、本番環境で障害・異常が発生したときに、チームが一貫した手順で対応するための一連のプロセスです。
SREの文脈では、単に「障害を直す手順」ではなく、次の3点を含む包括的な仕組みとして設計します。
- 検知: 障害をいち早く自動検知し、担当者に通知する
- 対応・復旧: 影響を最小化し、サービスを正常状態に戻す
- 振り返り: 同じ障害を繰り返さないための改善サイクルを回す
フローが設計されていないと、対応品質が担当者のスキルや経験に依存し、MTTRが高止まりします。Google SREブックでは、インシデント対応を「反復可能なプロセス(repeatable process)」として整備することの重要性を強調しています。
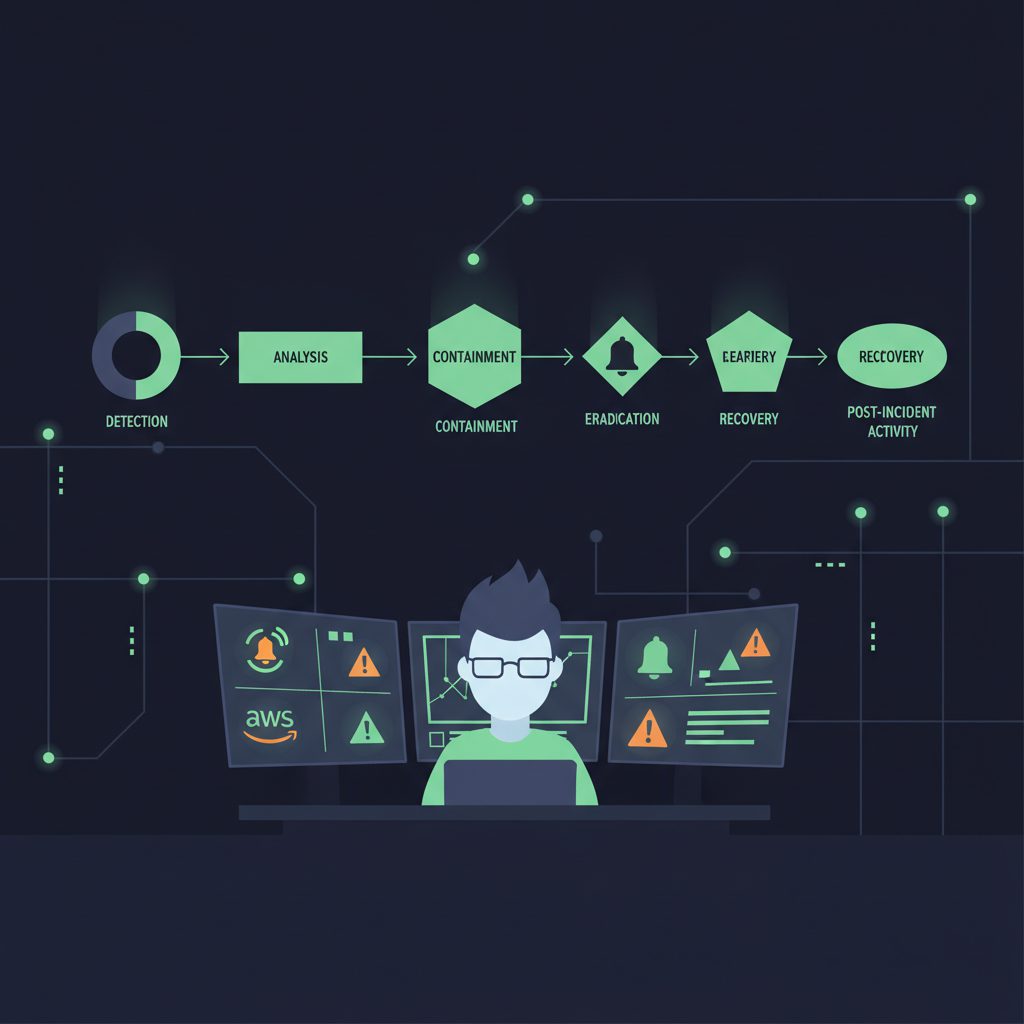
インシデント対応フローの全体像
インシデント対応は、大きく5つのフェーズに分けられます。
| フェーズ | 内容 | 目標時間の目安 |
|---|---|---|
| 1. 検知 | アラートでインシデントを検知・通知 | 〜5分 |
| 2. トリアージ | 影響範囲と深刻度を判定 | 〜10分 |
| 3. 対応・エスカレーション | 原因調査・暫定対処・必要に応じて応援要請 | 状況による |
| 4. 復旧 | サービスを正常状態に戻す | MTTRを最小化 |
| 5. 振り返り | ポストモーテムで根本原因分析・再発防止 | 72時間以内に開始 |
これらを「インシデントライフサイクル」として設計し、各フェーズで誰が何をするかを事前に定義しておくことが重要です。
フェーズ1: 検知(Detection)
インシデント対応の起点は、アラートの自動検知です。人間が気づくより前に、監視システムが異常を検出してオンコール担当者に通知する仕組みを作ります。
AWSでのアラート検知構成
AWSでは以下の構成が標準的です。
CloudWatch Alarm
│
▼
SNS Topic
│
├─ PagerDuty / OpsGenie(オンコール通知)
├─ Slack(チャンネル通知)
└─ メール(補助)
PagerDuty/OpsGenieを導入していない場合: SNS → Lambda → Slack Webhook 直結でも同等の通知フローを実現できます。まずこの構成から始めて、オンコール管理の複雑さが増してきたタイミングで専用ツールに移行するのが現実的な進め方です。
CloudWatch Alarmの設定例(CPU使用率が5分間80%超)
aws cloudwatch put-metric-alarm \
--alarm-name "HighCPUUtilization" \
--alarm-description "EC2 CPU utilization exceeds 80% for 5 minutes" \
--metric-name CPUUtilization \
--namespace AWS/EC2 \
--statistic Average \
--period 300 \
--evaluation-periods 1 \
--threshold 80 \
--comparison-operator GreaterThanOrEqualToThreshold \
--unit Percent \
--dimensions Name=InstanceId,Value=i-xxxxxxxxxxxxxxxxx \
--alarm-actions arn:aws:sns:ap-northeast-1:123456789012:incident-alert \
--ok-actions arn:aws:sns:ap-northeast-1:123456789012:incident-alert
アラート設計の原則
アラートは「多ければよい」わけではありません。アラート疲れ(Alert Fatigue)が起きると、重要なアラートを見逃すリスクが高まります。
設計時のポイントは以下の通りです。
- アクショナブルなアラートだけを通知する: 自動で解消するノイズはアラートにしない
- SLOに基づいた閾値を設定する: エラーバジェット消費率を監視する形が理想
- オンコール通知と情報通知を分ける: PagerDutyで起こすアラートとSlack通知だけのアラートを使い分ける
フェーズ2: トリアージ(Triage)
アラートを受けたオンコール担当者が最初にやることは、「これはどのくらい深刻か」を判定することです。
深刻度(Severity)の定義
深刻度を事前に定義しておくことで、対応の優先度と体制が即座に決まります。
| 深刻度 | 定義の例 | 対応体制 | 初動目標時間 |
|---|---|---|---|
| SEV1 | 本番サービスが全停止・主要機能が使えない | インシデントコマンダーを立てて全体対応 | 5分以内 |
| SEV2 | 一部機能の停止・パフォーマンスの著しい劣化 | 担当者2〜3名で対応 | 15分以内 |
| SEV3 | 限定的な影響・自動復旧の可能性あり | オンコール担当者が単独対応 | 30分以内 |
| SEV4 | 軽微な問題・翌営業日対応で問題なし | チケット化して後続対応 | 翌営業日 |
トリアージの確認項目
アラートを受けてから10分以内に以下を確認します。
□ 影響しているサービス・機能は何か
□ 影響しているユーザーの範囲はどれくらいか
□ エラーレート・レイテンシに異常はあるか
□ 直近のデプロイ・設定変更はあったか
□ 関連するCloudWatchアラームやログはあるか
□ 深刻度(SEV1〜4)はどれか
このチェックリストはRunbookに組み込んでおくと、初動のブレがなくなります。
フェーズ3: 対応・エスカレーション(Response & Escalation)
ロールの定義
インシデント対応では、役割を明確に分担することで混乱を防ぎます。特にSEV1・SEV2では以下のロールを立てます。
| ロール | 責任 |
|---|---|
| インシデントコマンダー(IC) | 対応全体の指揮・意思決定・ステークホルダーへの報告 |
| テクニカルリード | 原因調査・対処の実行 |
| コミュニケーションリード | 社内外への状況共有・ステータスページの更新 |
小規模なチームでは1人が複数ロールを兼任することもありますが、「指揮をとる人」と「手を動かす人」を分けることは意識してください。
暫定対処(Mitigation)の考え方
根本原因を特定する前に、まずサービスへの影響を止めることを優先します。
| 状況 | 暫定対処の例 |
|---|---|
| 直近デプロイが原因 | ロールバック |
| 特定ホストに問題 | ロードバランサーから切り離し |
| データベース過負荷 | 読み取りクエリをReadレプリカに逃がす |
| 外部API障害 | フォールバック処理を有効化 |
| キャッシュが空 | キャッシュウォームアップまたはオリジン直接参照に切り替え |
根本原因の解決には時間がかかることがあります。暫定対処でサービスを先に復旧させ、根本対応はインシデント収束後に落ち着いて行うのがSREの基本姿勢です。
エスカレーション基準
以下の条件に当てはまる場合は、迷わずエスカレーションします。
□ SEV1: 5分以上原因が特定できない → 即エスカレーション
□ SEV2: 15分以上原因が特定できない → エスカレーション
□ SEV3: 30分以上解決の見通しが立たない → チームリーダーに報告
□ 自分のスコープ外のシステムが関与している可能性がある
□ お客様への通知が必要な規模の障害
□ データ損失・セキュリティインシデントの可能性がある
□ 深刻度をSEV2→SEV1に上げるべき状況になった
エスカレーションを「失敗」と捉える文化は危険です。迷ったら早めに声をかけることをRunbookに明記しておきます。
フェーズ4: 復旧(Recovery)
復旧フェーズの目標は、サービスを安定した正常状態に戻すことです。暫定対処でアクセスが回復した状態は「復旧」ではなく「安定化」であることに注意します。
復旧確認チェックリスト
□ エラーレートが正常範囲(SLOの誤差許容内)に戻っている
□ レイテンシが正常値に戻っている
□ アラームがOK状態に戻っている
□ 関連するメトリクス(スループット・キャッシュヒット率等)が正常
□ ステータスページを「復旧済み」に更新した
□ 影響を受けたユーザーへの通知を行った(必要な場合)
MTTR(平均復旧時間)の記録
インシデントごとに以下の時刻を記録しておきます。
| タイムスタンプ | 内容 |
|---|---|
detected_at |
アラートが発報した時刻 |
acknowledged_at |
担当者が対応開始した時刻 |
mitigated_at |
暫定対処が完了した時刻 |
resolved_at |
完全に復旧した時刻 |
これらのデータがあると、MTTD(平均検知時間)・MTTA(平均応答時間)・MTTRを計算でき、フローの改善指標として使えます。
フェーズ5: 振り返り(ポストモーテム)
インシデント対応の中で、長期的に最も価値があるのがこのフェーズです。ポストモーテムは、犯人探しではなく、システムとプロセスを改善するための文化的実践です。
ポストモーテムの基本原則
- blameless(非難なし): 個人を責めるのではなく、構造的な問題を探る
- 72時間以内に開始: 記憶と文脈が残っているうちに
- 適切な参加者を集める: 直接関係者は必須参加。間接的な関係者は議事録で共有でOK。参加者が多すぎると心理的安全性が下がるため、コアメンバー5〜7人を目安にする
ポストモーテムドキュメントの構成
## インシデント概要
- 発生日時・解決日時・影響時間
- 影響範囲(ユーザー数・機能・地域)
- 深刻度
## タイムライン
- 時系列で何が起きたかを記録(5W1H)
## 根本原因分析
- 「なぜ?」を5回繰り返す(5 Whys)
- 直接原因だけでなく根本原因を特定する
## 影響
- 技術的影響(エラー率・ダウンタイム等)
- ビジネス影響(売上・ユーザー体験への影響)
## 対応アクション
| アクション | 担当者 | 期限 | 優先度 |
|-----------|--------|------|--------|
| ○○の監視アラームを追加 | 田中 | 2026-05-01 | 高 |
## 学んだこと
- うまくいったこと
- うまくいかなかったこと
- 幸運だったこと
5 Whysの実践例
事象: 本番DBの接続プールが枯渇してサービスが停止した
Why 1: なぜ接続プールが枯渇したか?
→ 接続数が上限(100)を超えたから
Why 2: なぜ接続数が増えたか?
→ スロークエリが増加して接続を長時間保持したから
Why 3: なぜスロークエリが増加したか?
→ 前日のデプロイでインデックスのない列への結合クエリが追加されたから
Why 4: なぜインデックスなしのクエリがデプロイされたか?
→ ステージング環境のデータ量が少なく、パフォーマンス劣化を検出できなかったから
Why 5: なぜステージングで検出できなかったか?
→ クエリのExplain分析がデプロイ前チェックに含まれていなかったから
→ 根本原因: デプロイ前チェックにスロークエリ検出が含まれていない
→ 対応: CIにExplain分析ステップを追加する
表面的な「接続プール上限を増やす」だけでは再発します。根本原因まで掘り下げることで、同じクラスの障害が次に起きにくい構造を作ります。
よくある失敗パターンと対策

失敗1: アラートが多すぎてオンコールが疲弊する
症状: 深夜に鳴るアラートの大半が自動復旧するノイズ
対策:
– アラートを「オンコール通知」「Slack通知のみ」「記録のみ」の3段階に分ける
– 自動復旧するアラームには ok-action のみ設定し、起床通知を出さない
– アラートノイズ率(自動復旧したアラートの割合)を週次で振り返り、継続的に改善する
失敗2: ポストモーテムが開催されない
症状: インシデントが収束したらそのまま次の仕事に移ってしまう
対策:
– SEV1・SEV2はポストモーテム開催を必須ルールにする
– インシデントチケットに「PM開催完了」を完了条件として設定する
– 30分〜1時間の軽量フォーマットからスタートする(完璧を求めない)
失敗3: 対応が属人化している
症状: 「Aさんがいれば解決できる」というインシデントが多い
対策:
– RunbookをWikiやConfluenceに整備し、誰でも参照できるようにする
– オンコールローテーションを実施して、複数人がシステムを把握している状態にする
– ゲームデイ(障害訓練)で平時からインシデント対応を練習する
失敗4: ロールが不明確で「誰かがやってると思った」が起きる
症状: 対応中に誰も全体を指揮しておらず、情報が錯綜する
対策:
– インシデント開始直後に「今日のICは〇〇さん」を明示する
– Slackチャンネルの冒頭に IC: @田中 / Tech: @鈴木 を固定投稿する
本番環境での注意点・ベストプラクティス
1. GameDay(ゲームデイ)で定期的に訓練する
フローは設計しただけでは定着しません。AWS Fault Injection Simulator(FIS)や手動での障害注入を使い、平時に「疑似インシデント」を体験する機会を作ります。
年1〜2回のGameDayで以下を確認します。
– アラートが正しくオンコール担当者に届くか
– Runbookに従って対応できるか
– 復旧にかかる時間は想定内か
2. インシデントチャンネルを専用化する
対応中のSlackチャンネルは専用のものを立てます。
#incident-yyyymmdd-{サービス名}
例: #incident-20260420-payment-api
既存のアラートチャンネルや雑談チャンネルに混じると、情報が流れてしまいます。インシデント専用チャンネルを立てることで、後からタイムラインを追いやすくなります。
3. ステータスページを更新する
ユーザー向けのステータスページ(Statuspage.io等)を用意している場合、インシデント発生後15分以内に「調査中」ステータスを更新します。
「何も言わない」ことがユーザーの不安を最大化します。内容が薄くても「認識しています・対応中です」という情報を出すだけで、問い合わせ数を大幅に減らせます。
4. エラーバジェットとインシデントを連動させる
SLOとエラーバジェットを管理している場合、インシデントのたびにバジェット消費量を記録します。
例)99.9% SLO(月間許容ダウンタイム: 43.8分)
→ 今回のインシデント: 25分のダウンタイム
→ 残りエラーバジェット: 18.8分(57%消費)
エラーバジェットが20%を切ったら、機能開発よりも信頼性改善を優先するという意思決定ルールを持つことで、組織として正しいトレードオフができます。
まとめ
インシデント対応フローの設計ポイントをまとめます。
- 検知: CloudWatch Alarm + SNS で自動検知・通知。アラートはノイズを排除してアクショナブルなものに絞る
- トリアージ: SEV1〜4の深刻度定義を事前に決め、10分以内に影響範囲と対応体制を確定させる
- 対応: IC・テクニカルリード・コミュニケーションリードのロールを明確化。暫定対処でまず影響を止める
- 復旧: エラーレート・レイテンシ・アラーム状態の正常化を確認してから「復旧完了」とする
- 振り返り: 72時間以内にblamelessポストモーテムを開催し、対応アクションを具体的なタスクとして記録する
インシデント対応の品質は、フローの設計と継続的な改善の積み重ねで上がります。まずトリアージの深刻度定義とRunbookの整備から着手するのが、現場で最も効果が出やすいアプローチです。
関連記事
– SLI・SLO設計の実践方法 – CloudWatchでエラーバジェットを管理する
– CloudWatch Logsの活用ガイド – ログ監視・アラート設定の実践
– SRE転職のリアル – 面接でよく聞かれるSLO・インシデント対応の答え方

コメント