
SRE転職の技術面接で、「SLOを設計した経験はありますか?」「インシデント対応のフローを説明してください」と聞かれて、頭が真っ白になった経験はないでしょうか。
このような質問は「知識を問う」のではなく、実際に現場で使えるかどうかを見極めるために出題されます。教科書的な定義を丸暗記しても、面接官の期待には応えられません。
本記事では、SLO・エラーバジェット・インシデント対応に関してよく出る質問を15問ピックアップし、面接官が期待する答え方のポイントと模範解答例を解説します。
この記事でわかること
– SLO・SLI・SLAの違いを面接で正確に説明する方法
– エラーバジェットの概念と、面接での答え方のコツ
– インシデント対応フローを体系的に説明する構成
– 「経験がない場合」の答え方と準備のしかた
– 面接官が実際に見ているポイント(知識 vs 実践力)
前提条件
本記事はSRE転職を目指しているインフラ・バックエンドエンジニアを対象にしています。基本的なSREの概念(SLO・SLI・SLAの定義)については既知のものとして解説します。

SLO・SLI・SLAに関する面接質問
Q1:SLO・SLI・SLAの違いを説明してください
面接官が見ているポイント: 単なる定義の暗記ではなく、3つの関係性を実務の文脈で理解しているか。
模範解答例:
SLAはサービス提供者が顧客と締結する契約上の保証水準です。SLOはその内部目標値で、SLAより高め(例:SLAが99.9%なら社内SLOは99.95%)に設定します。SLIはその目標を測定する指標そのもので、たとえば「正常レスポンス数 ÷ 全リクエスト数」といった計算式です。
現場では「SLIを計測して、SLOを守れているか監視し、SLAを超えて壊れないようにバッファを持たせる」という三層構造で管理します。
差がつくポイント:
– SLAとSLOに「差を設ける理由」まで説明できると高評価
– 「マーケティング的な契約数値と、エンジニアリング的な運用目標は分けて考える」という観点を加えると実践力が伝わる
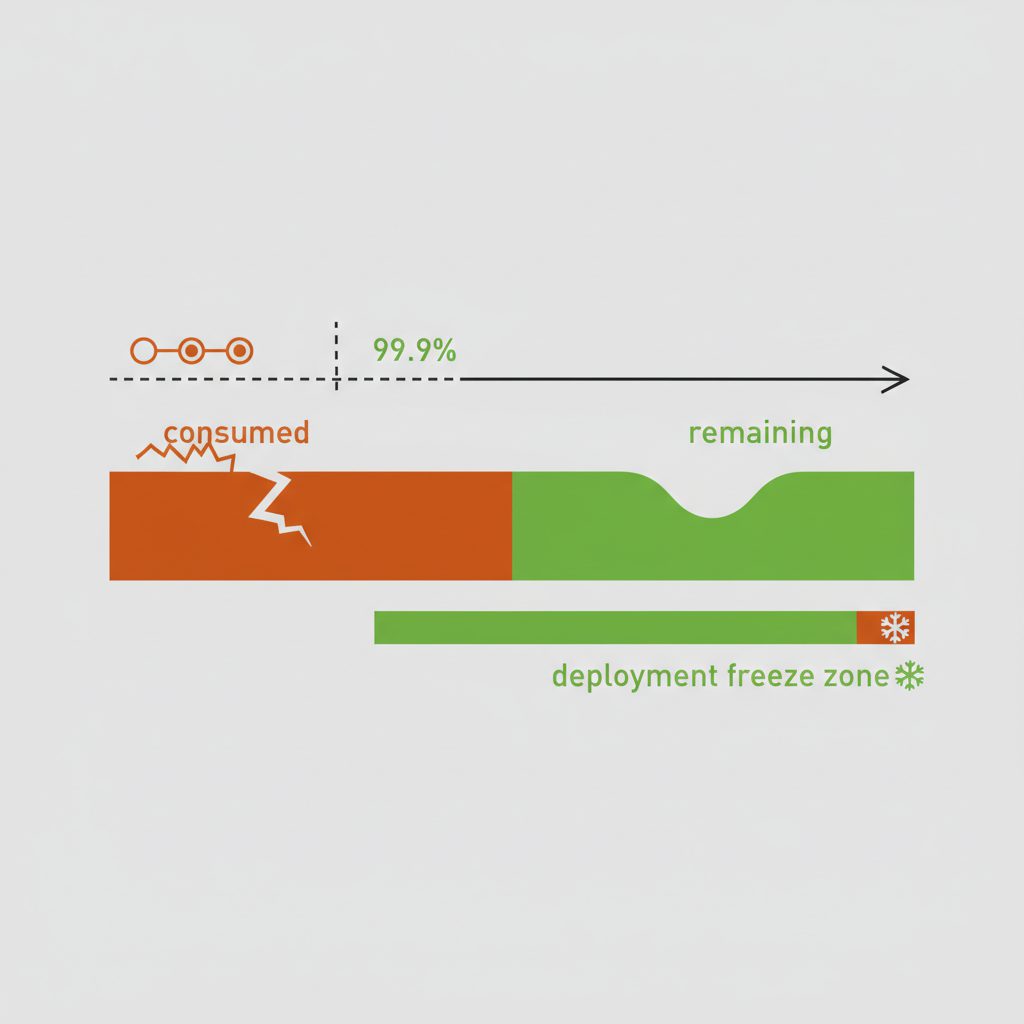
Q2:エラーバジェットとは何か、どのように活用しますか?
面接官が見ているポイント: エラーバジェットを「制約」ではなく「開発速度との調整弁」として理解しているか。
模範解答例:
エラーバジェットは「SLOを下回ってよい余裕」のことです。たとえばSLOが99.9%であれば、月間約43分間のダウンタイムが許容されます。この43分を「バジェット」として扱い、残量に応じてリリース速度を調整します。
エラーバジェットが十分残っているうちは積極的にデプロイし、消費が早い場合はリリースを止めて信頼性改善にフォーカスします。これにより「なぜ今リリースを止めるのか」をデータに基づいて開発チームに説明できます。
差がつくポイント:
– 「開発チームとSREチームの合意形成ツールとして使った」という経験があれば具体的に話す
– 「SLO違反が続いた時のプロセス(エスカレーション・凍結ポリシー)」まで言及できると実務経験が伝わる
Q3:SLOを新規に設計するとしたら、どのように進めますか?
面接官が見ているポイント: SLO設計を机上の作業ではなく、ステークホルダー調整込みのプロセスとして捉えているか。
模範解答例:
まずユーザーの「重要なユーザージャーニー」を特定します。全てのエンドポイントにSLOを設ける必要はなく、ユーザー体験に直結する3〜5の重要パスに絞ります。
次にSLIとして何を計測するか決めます。可用性ならリクエスト成功率、レイテンシなら95パーセンタイル応答時間などです。その後、過去90日分のメトリクスを見てベースラインを把握し、SLO値を設定します。
最後にプロダクトオーナーとビジネスサイドとSLO値を合意します。技術的に可能な数値ではなく、ビジネス要件とのバランスを取ることが重要です。
差がつくポイント:
– 「既存サービスにSLOを後付けするケース」と「新規サービスで設計するケース」の違いに触れると深みが出る
– SLOを設けなかった場合の問題(「何を守るべきか曖昧になり、インシデントの優先度判断ができない」)を対比で説明できると説得力が増す
Q4:SLOの数値は何パーセントに設定すべきですか?
面接官が見ているポイント: 「99.999%が最善」という思い込みがなく、コストとのトレードオフを理解しているか。
模範解答例:
一概に高ければ良いわけではありません。99.999%(5ナイン)を達成するには多重冗長化・ホットスタンバイ・ゼロダウンタイムデプロイなどの追加投資が必要で、コストが指数的に上がります。
まず「このサービスがX分落ちたら、ビジネスにどの程度の損失が出るか」を算出し、そのコストと信頼性確保のインフラコストを比較して決定します。社内業務ツールなら99.5%で十分なことも多く、決済系なら99.99%以上が求められます。
差がつくポイント:
– 「Googleは4ナインを基準に設計することが多い」など外部事例を引用できると説得力が上がる
インシデント対応に関する面接質問

インシデント対応フロー全体像
面接で「インシデント対応を説明してください」と聞かれた場合、以下のフローを軸に答えると体系的な印象を与えられます。
graph TD
A["🚨 アラート検知
(CloudWatch / Datadog)"] --> B["初期トリアージ
重大度分類 P1/P2/P3"]
B --> C{"P1 重大障害?"}
C -->|Yes| D["インシデント宣言
担当者アサイン・Slackチャネル開設"]
C -->|No| E["P2/P3 対応
通常フローで処理"]
D --> F["原因調査
ログ・メトリクス確認"]
F --> G["一時対処(ミティゲーション)
トラフィック切り替え・ロールバック"]
G --> H["サービス復旧確認
SLO ダッシュボード確認"]
H --> I["ステークホルダー報告
影響範囲・復旧時刻を通知"]
I --> J["ポストモーテム作成
タイムライン・再発防止策"]
J --> K["アクションアイテム登録
チケット化・オーナー割当"]
K --> L["恒久対策実施
本番反映・モニタリング強化"]
Q5:インシデント対応のフローを説明してください
面接官が見ているポイント: 「対応した」で終わらず、検知→トリアージ→対処→振り返りという一連のサイクルを回せるか。
模範解答例:
大きく5フェーズに分けています。まず「検知」でアラートが発火したら初動として重大度(P1〜P3)を判定します。P1であれば即座にインシデント宣言し、Slackに専用チャネルを開設してインシデントコマンダーをアサインします。
次に「調査・ミティゲーション」で、まず影響を止めることを優先します。根本原因の特定より先に、ロールバックやトラフィック切り替えで被害を最小化します。
復旧後は「コミュニケーション」として、影響時間・影響ユーザー数・暫定対処内容をステークホルダーに共有します。そして48〜72時間以内に「ポストモーテム」を作成し、再発防止アクションをチケット化します。
差がつくポイント:
– 「根本原因の特定より先に影響を止める」という優先順位の考え方を明確に述べると高評価
– ポストモーテムを「責任追及ではなく学習の場として行う」という文化的観点を加えると理解の深さが伝わる
Q6:ポストモーテムとは何ですか?どう書きますか?
面接官が見ているポイント: ポストモーテムを単なる障害報告書と混同していないか。「blameless(責任追及なし)」の文化を理解しているか。
模範解答例:
ポストモーテムは障害後に行うシステムと組織の学習プロセスです。重要なのは「誰が悪いか」ではなく「システムのどこに脆弱性があったか」を分析することです。Googleが提唱するblameless postmortemの考え方です。
構成は「インシデントサマリー → タイムライン → 根本原因分析(5 Whys等)→ 再発防止アクション(担当者・期限付き)」です。特に再発防止アクションは必ずチケット化して追跡可能にします。書きっぱなしにして実施されないポストモーテムは、次の障害を生む温床になります。
差がつくポイント:
– 「5 Whys分析の具体例」を一つ挙げられると実用的な理解を示せる
– 「ポストモーテムのアクションアイテム消化率を追跡していた」など運用の継続性に触れると実践力が伝わる
Q7:MTTR・MTTDとは何ですか?改善のためにどんな施策を取りますか?
面接官が見ているポイント: 概念を知っているだけでなく、実際に数値改善に向けたアプローチを持っているか。
模範解答例:
MTTDはMean Time To Detectで検知までの平均時間、MTTRはMean Time To Repairで復旧までの平均時間です。
MTTD改善には「アラートの精度向上」が直接効きます。ノイズが多すぎるとアラート疲れが起き、本当の障害を見逃します。誤検知率を下げて重要アラートのS/N比を高めることが優先です。具体的には閾値の見直しと、複数メトリクスの組み合わせ条件でのアラート設定です。
MTTR改善には「ランブックの整備」が効果的です。よくある障害パターンの対処手順を事前に文書化しておくことで、深夜のオンコールでも迷わず対応できます。加えてロールバック手順の自動化で復旧時間を短縮できます。
Q8:オンコール対応の経験を教えてください
面接官が見ているポイント: オンコール経験の有無だけでなく、持続可能なオンコール体制の考え方を持っているか。
模範解答例(経験あり):
X社では週次ローテーションのオンコールをX人チームで回していました。月間のアラート件数が多い時期は1週間で20件近い通知があり、MTTD改善を目的にアラートチューニングを実施しました。不要なアラートを半分程度削減し、疲弊感が下がりました。
オンコールの健全性を保つため「深夜対応後は翌日の業務開始を遅らせる」「週間アラート件数が一定を超えたら即チームレビュー」というポリシーを設けていました。
模範解答例(経験なし):
直接のオンコール経験はまだありませんが、オンコール体制の設計については学習しています。Googleの「SRE本」で推奨されているように、週の対応件数が多すぎる状態は持続不可能で、アラートチューニングや自動化で件数を減らすことが前提だと理解しています。入社後はシャドーオンコールから始めてチームのやり方を学びたいと考えています。
Q9:あなたが対応した中で最も困難だったインシデントを教えてください
面接官が見ているポイント: 技術力だけでなく、プレッシャー下での判断力・コミュニケーション能力を見ている。
答え方の構成(STAR法):
| 要素 | 内容 |
|---|---|
| Situation | どんなサービスで、何が起きたか |
| Task | あなたの役割・責任範囲 |
| Action | 具体的に何をしたか(判断・コミュニケーション含む) |
| Result | 結果と学んだこと |
模範解答例:
過去に、本番データベースへの大量のスロークエリが原因でAPIレスポンスタイムが10倍に跳ね上がったP1インシデントがありました。私はインシデントコマンダーとして対応しました。
まずトラフィックの一部を旧バージョンに切り替えて影響範囲を限定しながら調査を続けました。原因は直前のデプロイで追加されたN+1クエリで、インデックス不足が重なっていました。一時的にそのエンドポイントを無効化し、インデックス追加後に再開しました。
この経験からデプロイ前のスロークエリログレビューをCIに組み込むことを提案し、同種の問題を予防できるようになりました。
面接でよく出る追加質問 5選
Q10:SLOとKPIはどう違いますか?
SLOはサービスの信頼性(落ちないか・遅くないか)を定量化したものです。KPIはビジネス成果(売上・DAU等)の指標です。SLOが下がると長期的にKPIも下がりますが、両者は異なる軸で管理します。SRE的には「SLOを守ることがKPI達成の前提条件」という位置づけです。
Q11:カナリアリリースとブルーグリーンデプロイの違いを説明してください
カナリアリリースはトラフィックの一部(例:5%)だけに新バージョンを流し、問題がなければ段階的に割合を増やします。ブルーグリーンは新旧2環境を並行稼働させ、一括切り替えします。カナリアは影響範囲を限定できる一方で管理が複雑、ブルーグリーンは切り替えがシンプルですがコストが高い、というトレードオフがあります。SLOの観点では、カナリアの方がエラーバジェット消費を抑えながらリリースできます。
Q12:SLOを守るためにリリースを止めた経験はありますか?
経験ある場合: 具体的な状況・判断の根拠・開発チームとのコミュニケーション方法を話す
経験ない場合:
実施経験はまだありませんが、エラーバジェットポリシーとしてSLOの消費率が一定を超えた場合はデプロイ凍結するルール設計が重要だと理解しています。「なぜ止めるか」をデータで示せることが、開発チームとの摩擦を最小化するポイントだと考えています。
Q13:アラートの閾値はどのように決めますか?
静的な閾値だけに頼ると、トラフィックのピーク時に誤検知が増えます。ベースラインとなる正常状態を計測し、その統計的なばらつきに基づいて動的に閾値を設定するアプローチが有効です。たとえばCloudWatchであればAnomaly Detectionを使い、過去のパターンから外れた値をアラートにできます。また「何分間継続した場合にのみ発火する」という条件を加えて一時的なスパイクによるノイズを減らします。
Q14:SREとしてのキャリアで、最も重視するスキルは何ですか?
技術スキルの中では「オブザーバビリティの設計力」を最重視しています。どれだけ良いシステムを作っても、見えていないと問題に気づけません。メトリクス・ログ・トレースの三本柱を適切に設計できることが、全ての改善活動の土台になると考えています。
非技術スキルとしては「開発チームと信頼関係を築く力」です。SREは「信頼性という名のサービスを開発チームに提供するプロバイダー」という考え方で動いており、技術的な提案を受け入れてもらうには信頼が前提です。
Q15:「SREのポジションは求めていますが、インシデント対応の経験がない」場合はどう答えますか?
面接官が見ているポイント: 正直さと、学習・準備への姿勢。経験不足を誠実に認めた上で、補完する取り組みを示せるか。
模範解答例:
本番環境でのインシデントコマンダー経験はまだありません。ただ以下の準備を進めています。
- Google SRE本・SRE Workbookを通読し、インシデント対応の理論を学習
- 個人のAWS環境でCloudWatchアラート・ダッシュボードを設計し、意図的に障害を発生させて対応練習
- ポストモーテムのテンプレートを用意し、発生した問題を小さいものでも書き残す習慣
入社後はシャドーオンコールから始め、実際のチームのやり方を学びながら早期に戦力になりたいと考えています。

まとめ:SRE技術面接で差をつける3つのポイント
SRE技術面接のSLO・インシデント対応に関するポイントをまとめます。
① 定義より「なぜ使うか」を語る
SLOとSLIの定義は多くの候補者が答えられます。差がつくのは「なぜエラーバジェットが必要か」「なぜblamelessポストモーテムが重要か」という理由・背景の説明です。
② 数値・具体例を入れる
「99.9%のSLOなら月間43分のダウンタイムが許容される」「N+1クエリが原因でレスポンスが10倍」のように、具体的な数字や事例を交えると実践力が伝わります。
③ 経験ない場合は学習過程と準備を示す
経験不足を認めた上で「このように準備している」と具体的に示せる候補者は、面接官から「素直に成長できる人」と評価されます。嘘の経験を盛るより格段に高評価につながります。
本記事ではSLO・インシデント対応に特化した面接対策を解説しました。続編ではAWS・Kubernetes・IaCに関する技術面接対策を解説します。
関連記事
本記事の内容は2026年4月時点の情報に基づいています。

コメント