
Googleが公開した書籍「Site Reliability Engineering: How Google Runs Production Systems」(通称SRE本)は、SREを学ぶエンジニアにとって最も重要な教科書の一つです。
しかし実際に読み始めると、「概念の定義が曖昧なまま読み進めてしまう」「各章の繋がりが見えにくい」という壁にぶつかることがあります。SRE本は前提知識なしに読むには概念密度が高く、用語の定義を押さえないまま進むと理解が浅くなります。
この記事では、SRE本を読む前に理解しておくべき10の基本概念を整理します。これらを把握した上でSRE本を読むことで、各章の意図や設計思想がより深く理解できるようになります。
この記事でわかること
– SRE本を読む前に必要な10の概念とその定義
– 各概念がSRE本のどの文脈で登場するか
– 概念同士の関係性と全体像
対象読者: SRE本を読もうとしているエンジニア、または一度読んだが理解が断片的だったと感じている方。CloudWatchやAWSの監視設計をある程度経験していることを前提とします。
- SRE本(Google SRE Book)とは何か
- 概念① SLI(Service Level Indicator)
- 概念② SLO(Service Level Objective)
- 概念③ SLA(Service Level Agreement)
- 概念④ エラーバジェット(Error Budget)
- 概念⑤ トイル(Toil)
- 概念⑥ オンコール(On-call)とアラート設計
- 概念⑦ ポストモーテム(Postmortem)とblameless文化
- 概念⑧ モニタリングとオブザーバビリティ
- 概念⑨ リリースエンジニアリングと段階的デプロイ
- 概念⑩ キャパシティプランニング
- 10概念の関係性と全体像
- SRE本の効率的な読み方
- まとめ
SRE本(Google SRE Book)とは何か
「Site Reliability Engineering: How Google Runs Production Systems」(O’Reilly Media / 2016年)は、Googleが自社のインフラ運用哲学と実践手法を体系化した書籍です。日本語版(O’Reilly Japan)のほか、英語版はGoogleが公式に無料でWeb公開しています。
SRE本は全34章構成で、信頼性の哲学・サービス管理・SLO設計・インシデント対応・プラクティスの展開方法まで幅広くカバーします。読み切るには相当な時間がかかりますが、SREとして仕事をする上で参照価値が高い内容が詰まっています。
問題は、SRE本が「用語の定義をしながら進む」構成になっているため、最初から読み始めると定義の理解に追われて全体像が見えにくい点です。以下の10概念を事前に整理しておくことで、SRE本の読書効率が大幅に向上します。
概念① SLI(Service Level Indicator)
SLIとは、サービスの信頼性を計測するための具体的な指標です。
SRE本では「信頼性はユーザーが感じるもの」という視点で設計が行われます。そのため、サーバーのCPU使用率のような「インフラ側の指標」ではなく、ユーザー体験に直結する指標をSLIとして選びます。
代表的なSLIの例:
| サービス種別 | SLIの例 |
|---|---|
| Webアプリ | 成功レスポンス率(2xxの割合)、レスポンスタイム(95パーセンタイル) |
| バッチ処理 | ジョブ完了率、処理遅延時間 |
| データ基盤 | データの鮮度(更新遅延)、クエリ成功率 |
SLIはSLOの「何を測るか」を決める土台です。SRE本の第4章「Service Level Objectives」はこのSLI選択の議論から始まります。
概念② SLO(Service Level Objective)
SLOとは、SLIに対して設定する信頼性の目標値です。
「このAPIは95パーセンタイルのレスポンスタイムを200ms以内に保つ」「月間の成功レスポンス率を99.9%以上にする」といった形で定義します。
SLOはSREチームの活動の優先度判断軸になります。SLOを達成しているなら新機能開発を優先し、SLOが危うくなったら信頼性改善を優先するという判断ができます。
SRE本では、SLOを「チームの合意」として扱うことを強調しています。開発チームと運用チームが共通の目標値を持つことで、「信頼性 vs. 開発速度」のトレードオフを数値で議論できるようになります。
概念③ SLA(Service Level Agreement)
SLAとは、サービス提供者と利用者(顧客)の間で合意する信頼性の保証水準です。
SLO(内部目標)とSLA(外部約束)は明確に異なります。SRE本では「SLAはSLOより必ず低く設定する」という原則を示しています。
SLO(内部目標): 99.95%
SLA(外部保証): 99.9%
この差分(バッファ)が重要です。内部目標が99.95%なのに顧客への保証が99.99%では、SLO違反になっていないのにSLA違反になるという矛盾が生じます。SLAはSLOより「余裕を持って低く」設定することで、内部の障害対応余地を確保します。
概念④ エラーバジェット(Error Budget)
エラーバジェットとは、SLOで定義した「失敗を許容できる枠」のことです。
SLOが99.9%であれば、月間の許容ダウンタイムは約43.8分です。この43.8分が「エラーバジェット」です。
エラーバジェット(月)= 総時間 × (1 - SLO)
= 30日 × 24時間 × 60分 × (1 - 0.999)
= 43,200分 × 0.001
= 43.2分
エラーバジェットは「使い切るものではなく、計画的に使うもの」です。SRE本では、エラーバジェットが余っているならリリース速度を上げ、使い切りそうなら速度を落として信頼性改善に集中するという意思決定ツールとして使います。
現場でよくあるのは「エラーバジェットを数値化せずに感覚で運用している」ケースです。SRE本はこの感覚的な運用を「数値で合意した議論」に変えることを目指しています。
概念⑤ トイル(Toil)
トイルとは、手動で繰り返し行われる、自動化できるはずの運用作業のことです。
SRE本の第5章は「Eliminating Toil(トイルの排除)」です。SREがなぜトイル削減に取り組むのかを理解すると、SRE本の後半で語られる自動化への投資の意味が理解しやすくなります。
トイルの特徴:
- 手動: ロボット(スクリプト・自動化)ではなく、人間が実行する
- 繰り返し: 毎週・毎デプロイのたびに同じ作業をする
- 自動化可能: 工夫すれば機械に任せられる
- 価値が増えない: 作業しても技術的な価値(学習・改善)が生まれない
SRE本では「SREが費やすトイルの割合は業務時間の50%未満に抑える」という基準を示しています。トイルが50%を超えると、システム改善に使える時間がなくなり、SRE本来の役割を果たせなくなります。
概念⑥ オンコール(On-call)とアラート設計
オンコールとは、インシデントが発生した際に最初に対応する担当者が輪番制で待機する仕組みです。
SRE本の第11章では、オンコール設計における以下の問題を指摘しています。
- アラートが多すぎて担当者が疲弊する(アラート疲れ)
- 深夜に緊急度の低いアラートが飛んでくる
- 一人のエンジニアに依存した属人的な対応
「良いアラート」の条件として、SRE本は次の原則を示しています。
- 緊急対応が必要なもの(actionable)だけをページングする
- 情報提供だけのものはダッシュボードに留める
- アラートの数が増えるほど1件あたりの注意力が下がる
AWSのCloudWatchを使っている場合、「アラームの数が多いほど良い」という誤解があります。SRE本のオンコール設計を読む前に、「アラートはアクションを要求するもの」という基本を意識することが重要です。
概念⑦ ポストモーテム(Postmortem)とblameless文化
ポストモーテムとは、インシデント後に原因・影響・改善策を記録する振り返りドキュメントです。
SRE本が強調するのは「blameless(非難なし)」の姿勢です。障害の原因を「誰かの操作ミス」で終わらせるのではなく、「なぜその操作ミスが起きる状況が生まれたのか」というシステム的な原因に掘り下げます。
SRE本のポストモーテムの構成:
| セクション | 内容 |
|---|---|
| インシデント概要 | 発生日時・影響範囲・継続時間 |
| タイムライン | 検知から解決までの時系列 |
| 根本原因 | 直接原因と背景にある構造的問題 |
| 影響 | ユーザー・ビジネスへの影響 |
| アクションアイテム | 再発防止策と担当者・期限 |
blameless文化が根付いていないと、ポストモーテムは「責任の追求」の場になり、正直な情報共有が行われなくなります。SRE本はこの文化的な問題を技術的な話と同等に重要な要素として扱います。
概念⑧ モニタリングとオブザーバビリティ
モニタリングとは「何が起きているかを検知する仕組み」、オブザーバビリティとは「なぜ起きているかを調査できる状態」のことです。
SRE本の第6章では、モニタリングの目的を次の4つに整理しています。
- アラート: 即時対応が必要な問題の検知
- チケット: 近いうちに対応が必要な問題の記録
- ロギング: 後で参照するための記録
- ダッシュボード: システム状態の継続的な把握
オブザーバビリティ(観測可能性)は近年の分散システムで特に重視される概念です。サービスが複数のマイクロサービスで構成されている場合、単純なアラートだけでは「どのサービスのどのコードが原因か」を特定できません。ログ・メトリクス・トレースの3つを組み合わせた調査能力がオブザーバビリティです。
AWS環境ではCloudWatch(メトリクス・ログ)、X-Ray(トレース)がこれに対応します。
概念⑨ リリースエンジニアリングと段階的デプロイ
リリースエンジニアリングとは、ソフトウェアのビルド・テスト・デプロイを安全・再現可能な形で自動化する実践です。
SRE本の第8章では、Googleが実践するリリースエンジニアリングの哲学として「self-service model(開発チームが自分でリリースできる仕組み)」を紹介しています。
段階的デプロイの代表的な手法:
| 手法 | 概要 |
|---|---|
| カナリアリリース | 一部のサーバー・ユーザーだけに新バージョンを配布し、問題がなければ全体に展開 |
| ブルー/グリーンデプロイ | 新旧環境を並走させ、ロードバランサーの向き先を切り替える |
| フィーチャーフラグ | コードとは別にオン/オフを制御するフラグでデプロイと機能リリースを分離 |
リリースエンジニアリングの本質は「変更をいつでも安全に戻せる状態にする」ことです。SRE本はこれを「チームの自律性を高めながら信頼性を維持する手段」として位置づけています。
概念⑩ キャパシティプランニング
キャパシティプランニングとは、将来のリソース需要を予測し、過剰・不足なくリソースを確保する実践です。
SRE本の第18章では、キャパシティプランニングを「サービスの成長に応じた信頼性の維持」として扱います。リソースが不足すれば可用性が下がり、過剰ならコストが無駄になります。
SRE本が示すキャパシティプランニングのステップ:
- 需要予測: 過去のトラフィック増加率・季節変動・ビジネス計画から算出
- リソース見積もり: 予測トラフィックを処理するのに必要なサーバー・DB・ネットワーク帯域
- バッファの確保: 予測誤差・突発的なトラフィック増加に備えた余剰リソース
- 定期的な見直し: 実績vs予測を比較し、精度を改善する
AWS環境では、Auto Scalingによる動的スケーリングがキャパシティプランニングの一部を自動化します。ただしSRE本は「Auto Scalingに頼りすぎることへの注意」も指摘しており、スケールアップの余地がなくなった場合の対応策(アーキテクチャ見直し・キャッシュ導入)の重要性を強調します。
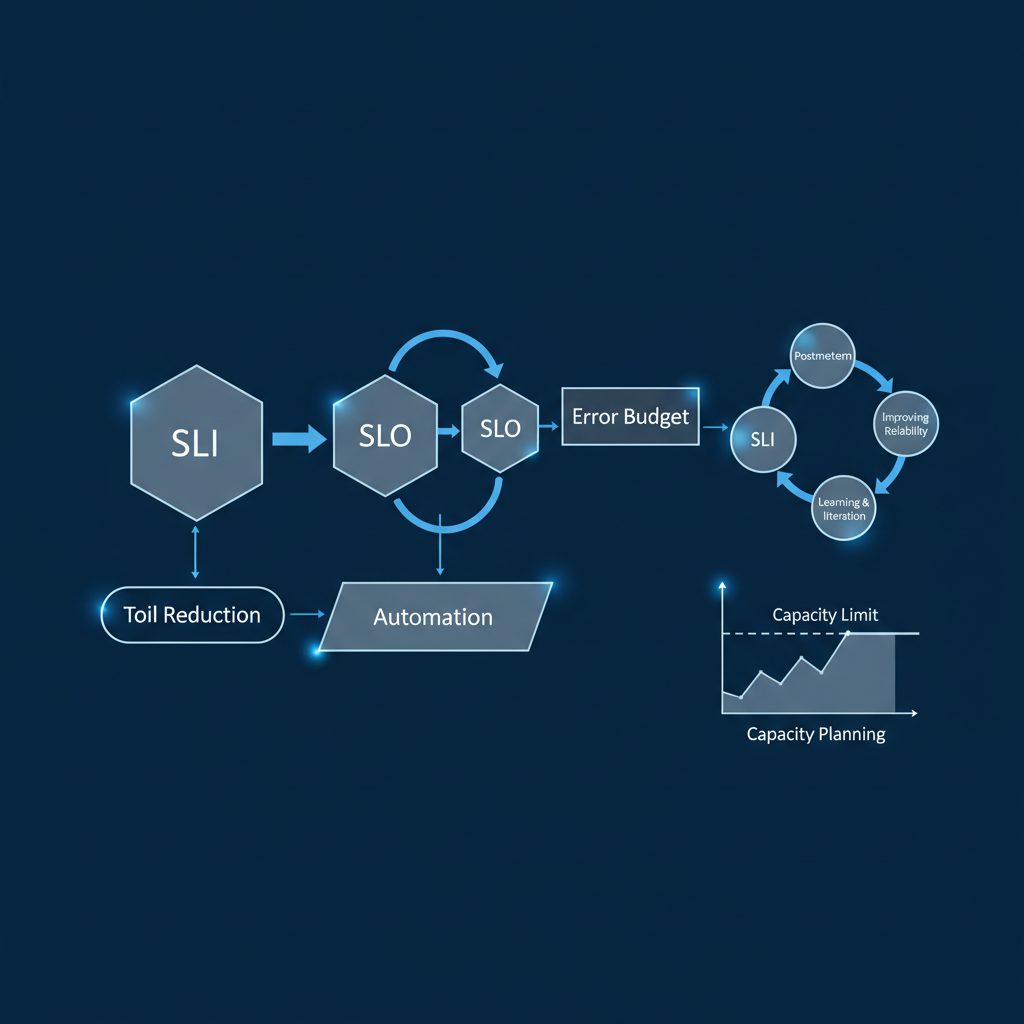
10概念の関係性と全体像
10の概念は独立しているのではなく、SRE本の中で以下のように連結しています。
【信頼性の定義】
SLI(何を測る) → SLO(目標値) → SLA(外部保証)
↓
エラーバジェット(許容余力)
↓
┌────────────────────────────┐
│ 余剰がある → リリース速度を上げる │
│ 枯渇しそう → 信頼性改善に集中 │
└────────────────────────────┘
【信頼性の維持】
モニタリング → アラート → オンコール対応 → ポストモーテム
↓
再発防止策 → SLO改善
【信頼性の向上】
トイル削減 + リリースエンジニアリング + キャパシティプランニング
SRE本は各概念を個別に解説しながら、「これらが組み合わさってどう機能するか」を繰り返し示します。読む前にこの全体像を頭に入れておくと、各章の位置づけが明確になります。
SRE本の効率的な読み方
SRE本は全34章ありますが、最初から全部読む必要はありません。以下の順序で読むと全体像を掴みながら実務に活かしやすくなります。
Step 1: 概念理解(まず読む章)
| 章 | タイトル | ポイント |
|---|---|---|
| 第1章 | Introduction | SREとは何か・なぜ必要かの哲学 |
| 第4章 | Service Level Objectives | SLI/SLO/SLA/エラーバジェットの定義 |
| 第5章 | Eliminating Toil | トイルの定義と削減の考え方 |
| 第6章 | Monitoring Distributed Systems | モニタリングの目的と設計 |
Step 2: インシデント対応(次に読む章)
| 章 | タイトル | ポイント |
|---|---|---|
| 第11章 | Being On-Call | オンコール設計と担当者の負荷管理 |
| 第12章 | Effective Troubleshooting | 障害調査の体系的なアプローチ |
| 第13章 | Emergency Response | 緊急対応時の判断フレームワーク |
| 第15章 | Postmortem Culture | ポストモーテムとblameless文化 |
Step 3: プラクティス展開(余裕があれば読む章)
| 章 | タイトル | ポイント |
|---|---|---|
| 第8章 | Release Engineering | リリースの自動化と段階的展開 |
| 第18章 | Software Engineering in SRE | SREが書くべきコードと自動化の投資 |
| 第28章 | Accelerating SREs | SREプラクティスを組織に広げる方法 |
まとめ
SRE本を読む前に押さえておくべき10の概念を整理しました。
- SLI/SLO/SLA: 信頼性を数値で定義し、合意するための3層構造
- エラーバジェット: SLOの許容余力を使って開発速度と信頼性をトレードオフで管理する
- トイル: 手動・繰り返し・自動化可能な作業を定義し、50%未満に抑える
- オンコール設計: アクションが必要なアラートだけをページングし、担当者の疲弊を防ぐ
- ポストモーテム: blameless文化でインシデントの根本原因を追求し、再発防止につなげる
- モニタリング: アラート・チケット・ログ・ダッシュボードの4目的を意識して設計する
- リリースエンジニアリング: 段階的デプロイと自動化でリリースリスクを最小化する
- キャパシティプランニング: 需要予測とバッファ確保で信頼性を継続的に維持する
この10概念を頭に入れた上でSRE本を読み始めると、各章の意図と設計思想がクリアに見えてくるはずです。
SREの実務スキルをAWSで体系的に学びたい方へ
本記事で紹介したSLO設計・エラーバジェット管理・インシデント対応・オブザーバビリティなどSRE本の概念を、AWS CloudWatchを使って実際に手を動かしながら学べるUdemyコースを公開しています。
SRE本の理論を「現場で使えるAWSの実装」に落とし込む内容です。


コメント